Publications
(†) denotes equal contribution
(*) denotes correspondance
denotes journal
denotes conference
denotes preprint
2026
- Federated learning for medical image analysis: Methods, challenges, and future directionsThu Thuy Le , Phuong-Nam Tran , Nhat Truong Pham , Balachandran Manavalan , Li Shen , Choong Seon Hong , and Duc Ngoc Minh Dang
In recent years, rapid technological advances have made artificial intelligence a global trend, significantly advancing the fields of medicine and healthcare. Meanwhile, concerns about information security and medical data privacy have also increased. Although many studies have collected data from hospitals to train centralized models, data sharing between medical facilities is often restricted and protected by law. Federated learning (FL) emerges as a promising solution, enabling model training across different medical facilities without sharing raw data, thereby safeguarding patient privacy and ensuring data security. Our study reviews key works on FL in medical image analysis (MIA) from 2020 to 2025. We systematically analyze major challenges, including data heterogeneity, non-independent and identically distributed data, missing labels, communication costs, and privacy risks during model updates. Additionally, this review covers emerging approaches such as semi-supervised learning, unsupervised learning, domain shift learning, advanced deep learning architectures, and personalized models within the context of FL. We aim to provide a comprehensive overview of the current research landscape, methods for addressing these challenges, and future directions for FL in MIA.
@article{le2026federated, title = {Federated learning for medical image analysis: Methods, challenges, and future directions}, author = {Le, Thu Thuy and Tran, Phuong-Nam and Pham, Nhat Truong and Manavalan, Balachandran and Shen, Li and Hong, Choong Seon and Dang, Duc Ngoc Minh}, journal = {Advanced Engineering Informatics}, volume = {76}, pages = {104976}, year = {2026}, publisher = {Elsevier}, doi = {10.1016/j.aei.2026.104976}, } - CONTRA-IL6: an interpretable hybrid convolutional neural network and Transformer framework for accurate prediction of interleukin-6-inducing peptides using protein language modelsDuong Thanh Tran , Nhat Truong Pham , Gwang Lee , Shaherin Basith , and Balachandran Manavalan
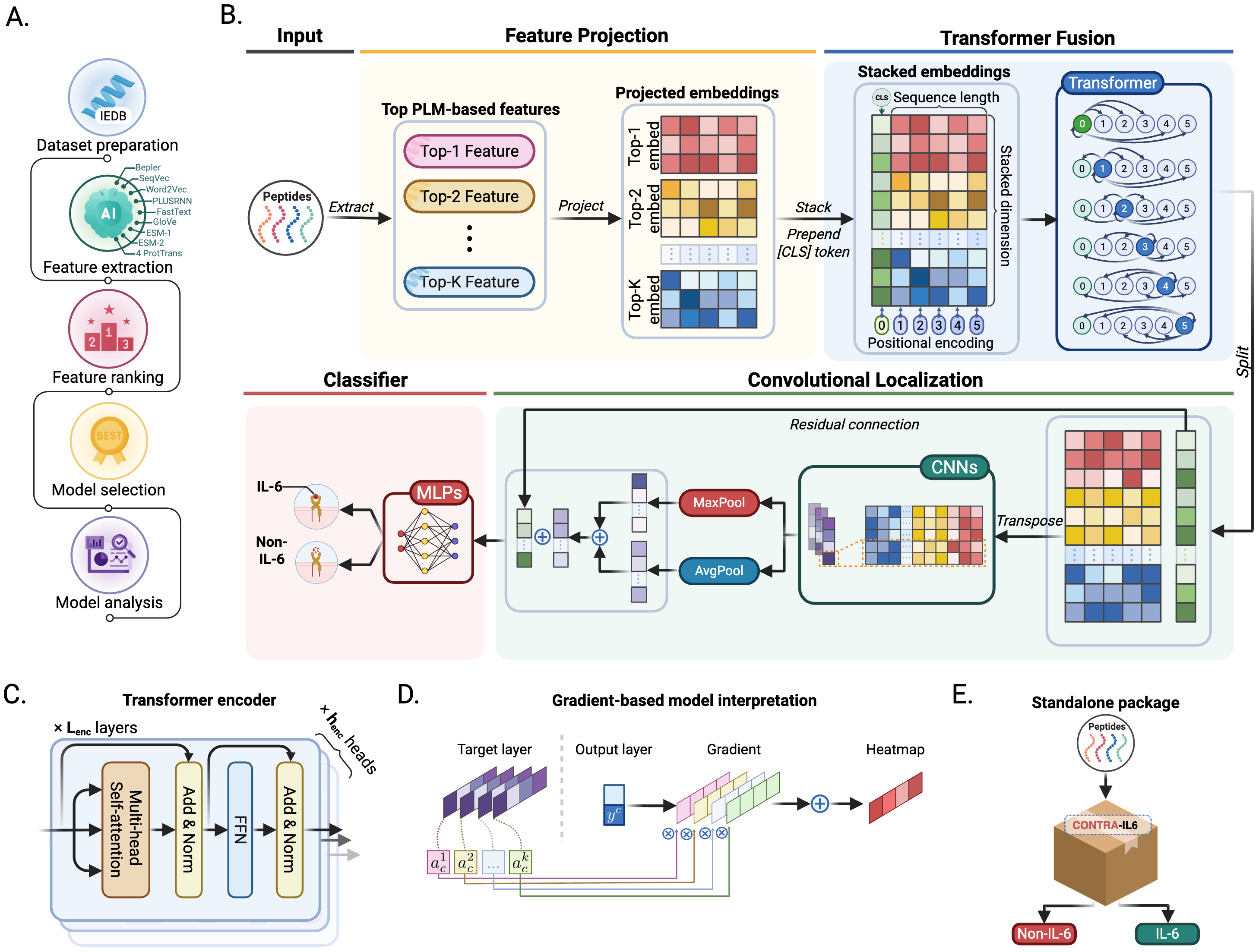
Interleukin-6 (IL-6) is a key immunomodulatory cytokine implicated in diverse physiological processes and pathological conditions, including autoimmune diseases, cancers, and cytokine storms. Immunogenic peptides capable of inducing IL-6 expression are key modulators of host immune responses and represent promising candidates for therapeutic design and epitope-based vaccine development. However, experimental identification of IL-6-inducing peptides remains laborious and unsuitable for large-scale screening. Although existing computational approaches show promise, many often struggle to capture both global contextual semantics and local motif-level features essential for peptide immunogenicity. To address these limitations, we present CONTRA-IL6, a novel deep learning framework that integrates Transformer fusion and convolutional localization modules with stacked pretrained protein language model embeddings to predict IL-6-inducing peptides. Comprehensive benchmarking on an independent dataset demonstrates that CONTRA-IL6 achieves superior predictive performance over six state-of-the-art predictors. Notably, it achieves the highest Matthews correlation coefficient (MCC, 0.504) and F1 (0.549) and improves over the best-performing existing method by 3.2% in MCC and 4.3% in F1, demonstrating balanced and robust performance. Feature space visualizations (uniform manifold approximation and projection, kernel density estimation) showed clear class separation, while 1D gradient-weighted class activation mapping++ highlighted strong attention to specific C-terminal regions. Crucially, we moved beyond these attribution methods by employing in silico mutagenesis, which causally confirmed the functional importance and physicochemical constraints. Ablation studies further confirmed the synergistic contribution of global and local modules to model performance. CONTRA-IL6 offers a robust, scalable, and interpretable solution for immunoinformatics research. The standalone package is freely available at https://pypi.org/project/contra-il6/ to facilitate broader community use.
@article{tran2026contra, title = {CONTRA-IL6: an interpretable hybrid convolutional neural network and Transformer framework for accurate prediction of interleukin-6-inducing peptides using protein language models}, author = {Tran, Duong Thanh and Pham, Nhat Truong and Lee, Gwang and Basith, Shaherin and Manavalan, Balachandran}, journal = {Briefings in Bioinformatics}, volume = {27}, number = {3}, pages = {bbag250}, year = {2026}, publisher = {Oxford University Press}, doi = {10.1093/bib/bbag250}, } - GinDB-AI: An integrated ginsenoside database and AI-driven platform for multidimensional information and biological activity predictionNguyen Doan Hieu Nguyen , Vinoth Kumar Sangaraju , Duong Thanh Tran , Nhat Truong Pham , Jae Youl Cho , and Balachandran Manavalan
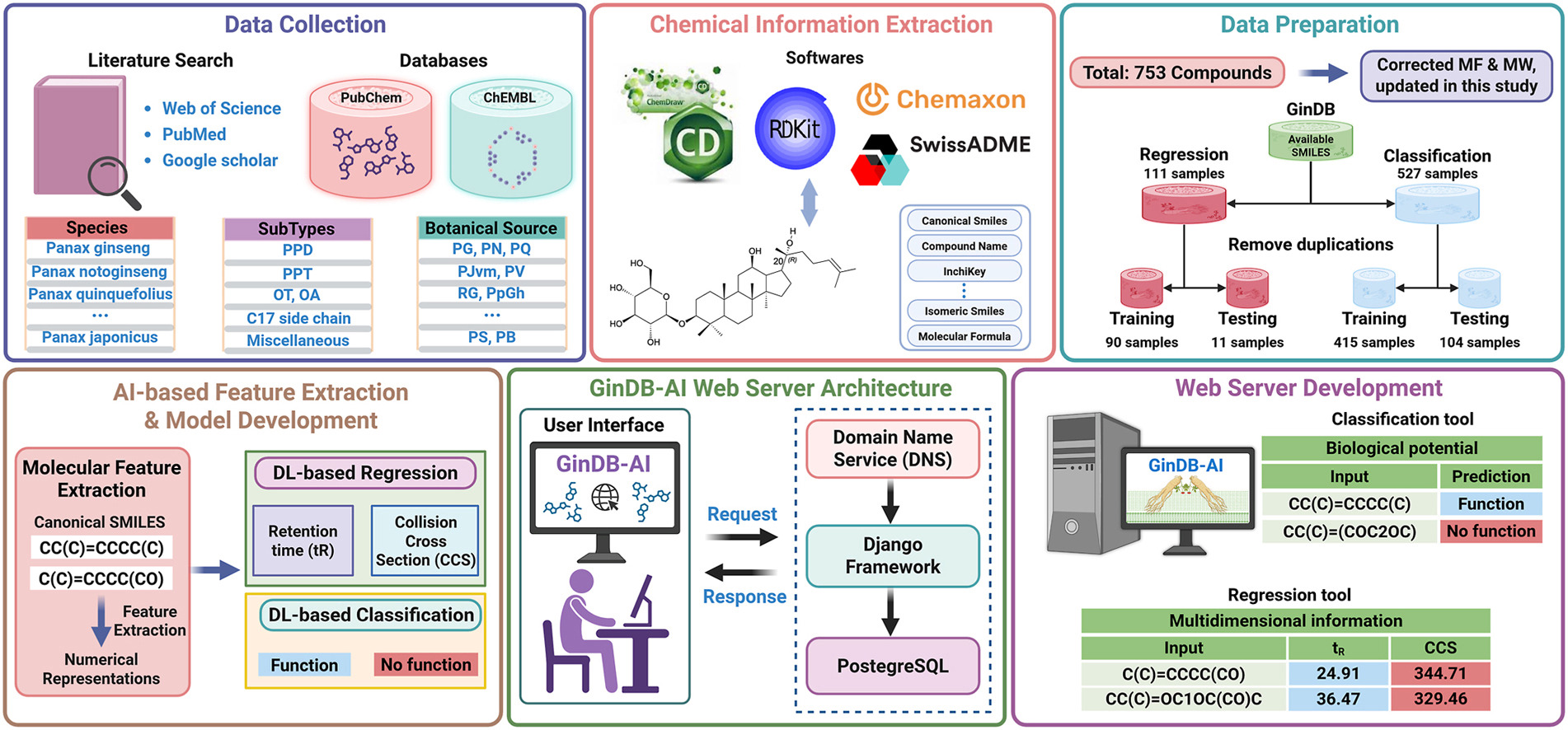
GinDB is a comprehensive database containing 753 standardized ginsenosides with curated and corrected data from 1963 to 2024. Integrated with GinDB-AI, a deep learning module for predicting bioactivity and physicochemical properties, the platform enables rapid structure-activity analysis and visualization. The freely accessible resource accelerates ginsenoside-based drug discovery and natural product research.
@article{nguyen2026gindb, title = {GinDB-AI: An integrated ginsenoside database and AI-driven platform for multidimensional information and biological activity prediction}, author = {Nguyen, Nguyen Doan Hieu and Sangaraju, Vinoth Kumar and Tran, Duong Thanh and Pham, Nhat Truong and Cho, Jae Youl and Manavalan, Balachandran}, journal = {Journal of Ginseng Research}, volume = {50}, number = {3}, pages = {100986}, year = {2026}, publisher = {Elsevier}, doi = {10.1016/j.jgr.2026.100986}, }
2025
- Mulaqua: An interpretable multimodal deep learning framework for identifying PMT/vPvM substances in drinking waterNguyen Doan Hieu Nguyen , Nhat Truong Pham , Hojin Seo , Leyi Wei , and Balachandran Manavalan
Drinking water is an essential resource for human health and well-being, still it faces increasing threats from contamination by chemical pollutants. Among the contaminants, persistent, mobile, and toxic (PMT) substances, along with very persistent and very mobile (vPvM) substances, have emerged as chemicals of significant concern due to their harmful effects on human health. Regulatory bodies have recognized them as emerging contaminants requiring stricter monitoring and management practices. Traditional experimental methods for detecting and characterizing these substances are often slow and resource-intensive. Therefore, there is a pressing need to develop efficient computational approaches to detect persistent, mobile, and toxic, or very persistent and very mobile (PMT/vPvM) substances rapidly and economically. Addressing this gap, we proposed Mulaqua, the first deep learning (DL) approach specifically designed for identifying PMT/vPvM substances. Mulaqua utilizes a novel multimodal approach combining molecular string representation with molecular image for the final prediction. To address the data imbalance issue in the training dataset, we employ a data augmentation strategy based on Simplified Molecular Input Line Entry System (SMILES) enumeration, which helped to achieve a balanced performance with the training accuracy (ACC), F1-score (F1), and Matthews correlation coefficient (MCC) score of 0.920, 0.590, and 0.548, respectively. Our study also includes interpretability analyses to elucidate how specific molecular architectures influence PMT/vPvM substances characterization, thereby providing meaningful insights. Mulaqua demonstrates excellent transferability, validated through rigorous evaluation of external datasets, which significantly improves performance compared to the baseline. Unlike previous methods, Mulaqua is now publicly available at https://github.com/cbbl-skku-org/Mulaqua/, holds significant potential as a proactive tool for early hazard identification and regulatory prioritization of PMT/vPvM substances in environmental risk management.
@article{nguyen2025mulaqua, title = {Mulaqua: An interpretable multimodal deep learning framework for identifying PMT/vPvM substances in drinking water}, author = {Nguyen, Nguyen Doan Hieu and Pham, Nhat Truong and Seo, Hojin and Wei, Leyi and Manavalan, Balachandran}, journal = {Journal of Hazardous Materials}, volume = {500}, pages = {140573}, year = {2025}, publisher = {Elsevier}, doi = {10.1016/j.jhazmat.2025.140573}, } - Federated Semi-Supervised FixMatch: Enhancing CutMix for Medical Image SegmentationThu Thuy Le , Nhut Minh Nguyen , Nhat Truong Pham , Phuong-Nam Tran , Nguyen Doan Hieu Nguyen , Phuong Luu Vo , Balachandran Manavalan , and Duc Ngoc Minh Dang
Previous studies on federated learning (FL) often assume that each client has access to fully labeled data. In reality, however, most hospitals and clinical facilities lack sufficient labeled data, as annotation is costly and requires highly skilled experts. The key challenge, therefore, is how to effectively train FL models when only a small portion of data at each client is labeled. Federated semi-supervised learning (FSSL) has emerged as a promising solution. From the perspective of big data, this challenge is further intensified by the large scale, heterogeneity, and non-IID nature of data distributions. These factors significantly affect training efficiency, making it crucial to fully leverage diverse unlabeled datasets while ensuring privacy and minimizing communication costs for large-scale FL deployment. In this study, we apply data augmentation in FSSL to make better use of unlabeled data together with the limited amount of labeled data. Specifically, we investigate the role of CutMix, a widely used patch-level augmentation technique, when combined with Federated FixMatch (FedFixMatch). We evaluate different strategies, including applying CutMix only to labeled data, only to unlabeled data, to both branches, or to mixed data, and examine their effects under varying annotation conditions and heterogeneous client distributions. Additionally, we examine the impact of CutMix on communication efficiency, convergence dynamics, and training stability within FedFixMatch. To the best of our knowledge, this work provides the first comprehensive benchmark of CutMix strategies in FSSL for medical image segmentation. Our results provide important guidance for developing efficient augmentation strategies that address the practical challenges of big data and FL.
@inproceedings{le2025federated, title = {Federated Semi-Supervised FixMatch: Enhancing CutMix for Medical Image Segmentation}, author = {Le, Thu Thuy and Nguyen, Nhut Minh and Pham, Nhat Truong and Tran, Phuong-Nam and Nguyen, Nguyen Doan Hieu and Vo, Phuong Luu and Manavalan, Balachandran and Dang, Duc Ngoc Minh}, booktitle = {2025 IEEE International Conference on Big Data BigData}, pages = {3462--3471}, year = {2025}, organization = {IEEE}, doi = {10.1109/BigData66926.2025.11402514}, } - xBitterT5: an explainable transformer-based framework with multimodal inputs for identifying bitter-taste peptidesNguyen Doan Hieu Nguyen† , Nhat Truong Pham† , Duong Thanh Tran , Leyi Wei , Adeel Malik , and Balachandran Manavalan
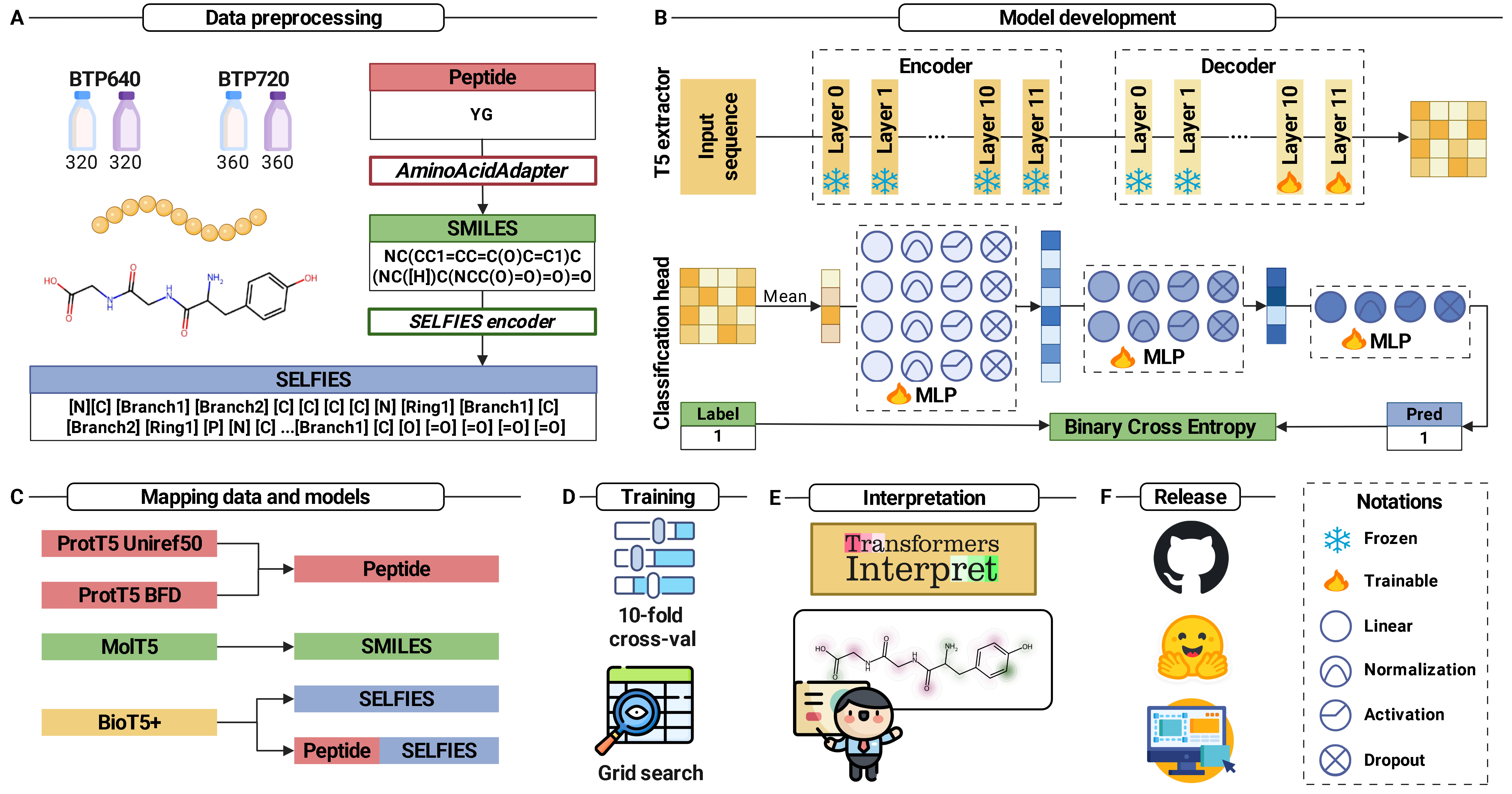
Bitter peptides (BPs), derived from the hydrolysis of proteins in food, play a crucial role in both food science and biomedicine by influencing taste perception and participating in various physiological processes. Accurate identification of BPs is essential for understanding food quality and potential health impacts. Traditional machine learning approaches for BP identification have relied on conventional feature descriptors, achieving moderate success but struggling with the complexities of biological sequence data. Recent advances utilizing protein language model embedding and meta-learning approaches have improved the accuracy, but frequently neglect the molecular representations of peptides and lack interpretability. In this study, we propose xBitterT5, a novel multimodal and interpretable framework for BP identification that integrates pretrained transformer-based embeddings from BioT5+ with the combination of peptide sequence and its SELFIES molecular representation. Specifically, incorporating both peptide sequences and their molecular strings, xBitterT5 demonstrates superior performance compared to previous methods on the same benchmark datasets. Importantly, the model provides residue-level interpretability, highlighting chemically meaningful substructures that significantly contribute to its bitterness, thus offering mechanistic insights beyond black-box predictions. A user-friendly web server (https://balalab-skku.org/xBitterT5/) and a standalone version (https://github.com/cbbl-skku-org/xBitterT5/) are freely available to support both computational biologists and experimental researchers in peptide-based food and biomedicine.
Scientific Contribution
We propose xBitterT5, a novel multimodal transformer-based framework for the identification of BPs. By utilizing the pretrained BioT5+ model, xBitterT5 effectively extracts high-level representations from both the peptide sequences and their corresponding SELFIES molecular representation. This dual-modality approach enables a more comprehensive understanding of the peptide sequence by leveraging its molecular string, leading to substantial improvements in performance across two benchmark datasets. Additionally, xBitterT5 offers interpretability by identifying key molecular substructures that contribute to bitterness, thereby providing mechanistic insights essential for peptide-based food and drug applications.
@article{nguyen2025xbittert5, title = {xBitterT5: an explainable transformer-based framework with multimodal inputs for identifying bitter-taste peptides}, author = {Nguyen, Nguyen Doan Hieu and Pham, Nhat Truong and Tran, Duong Thanh and Wei, Leyi and Malik, Adeel and Manavalan, Balachandran}, journal = {Journal of Cheminformatics}, volume = {17}, number = {1}, pages = {127}, year = {2025}, publisher = {Springer}, doi = {10.1186/s13321-025-01078-1}, } - HyPepTox-Fuse: An interpretable hybrid framework for accurate peptide toxicity prediction fusing protein language model-based embeddings with conventional descriptorsDuong Thanh Tran† , Nhat Truong Pham† , Nguyen Doan Hieu Nguyen , Leyi Wei , and Balachandran Manavalan
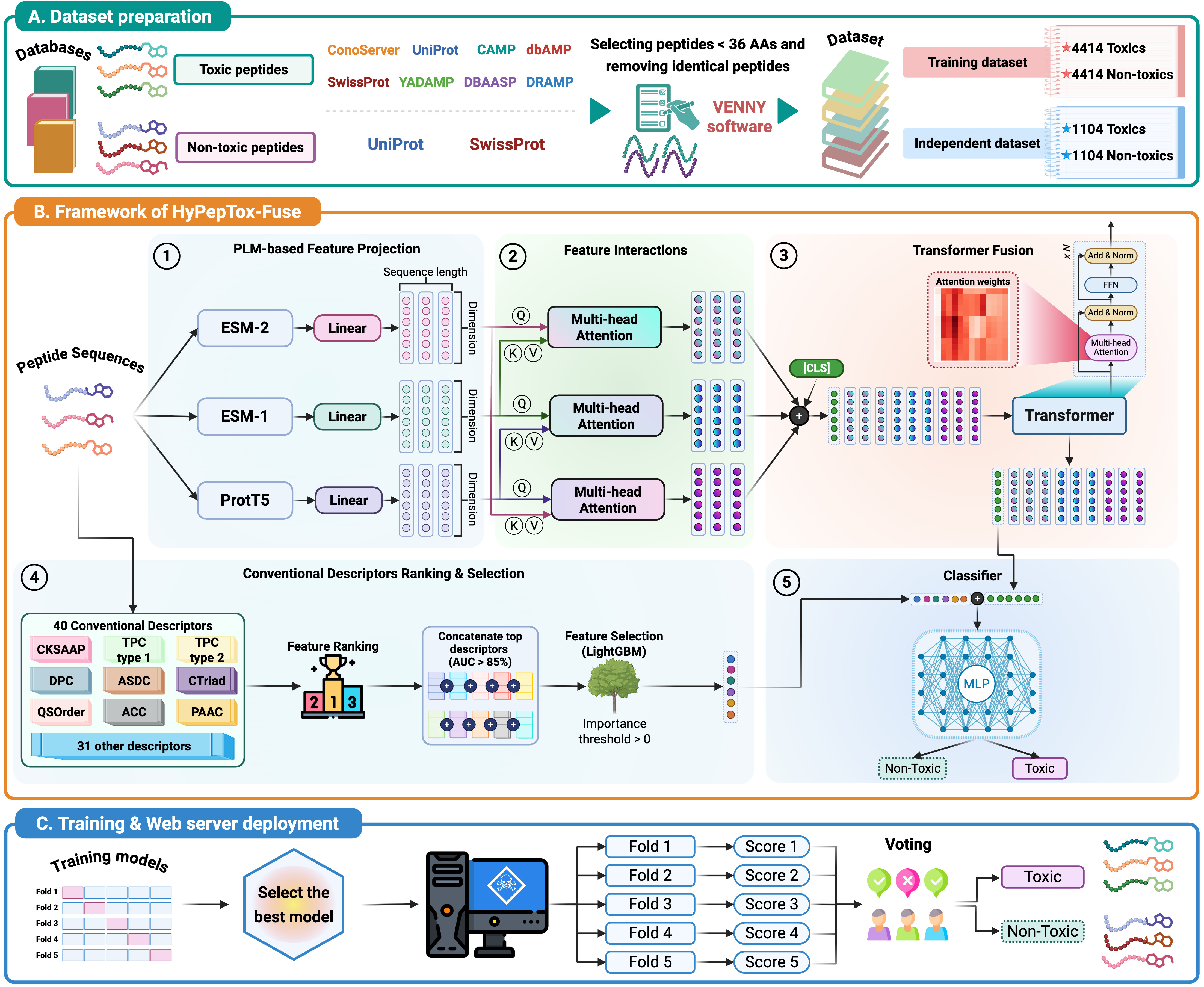
Peptide-based therapeutics hold great promise for the treatment of various diseases; however, their clinical application is often hindered by toxicity challenges. The accurate prediction of peptide toxicity is crucial for designing safe peptide-based therapeutics. While traditional experimental approaches are time-consuming and expensive, computational methods have emerged as viable alternatives, including similarity-based and machine learning (ML)-/deep learning (DL)-based methods. However, existing methods often struggle with robustness and generalizability. To address these challenges, we propose HyPepTox-Fuse, a novel framework that fuses protein language model (PLM)-based embeddings with conventional descriptors. HyPepTox-Fuse integrates ensemble PLM-based embeddings to achieve richer peptide representations by leveraging a cross-modal multi-head attention mechanism and Transformer architecture. A robust feature ranking and selection pipeline further refines conventional descriptors, thus enhancing prediction performance. Our framework outperforms state-of-the-art methods in cross-validation and independent evaluations, offering a scalable and reliable tool for peptide toxicity prediction. Moreover, we conducted a case study to validate the robustness and generalizability of HyPepTox-Fuse, highlighting its effectiveness in enhancing model performance. Furthermore, the HyPepTox-Fuse server is freely accessible at https://balalab-skku.org/HyPepTox-Fuse/ and the source code is publicly available at https://github.com/cbbl-skku-org/HyPepTox-Fuse/. The study thus presents an intuitive platform for predicting peptide toxicity and supports reproducibility through openly available datasets.
@article{tran2025hypeptox, title = {HyPepTox-Fuse: An interpretable hybrid framework for accurate peptide toxicity prediction fusing protein language model-based embeddings with conventional descriptors}, author = {Tran, Duong Thanh and Pham, Nhat Truong and Nguyen, Nguyen Doan Hieu and Wei, Leyi and Manavalan, Balachandran}, journal = {Journal of Pharmaceutical Analysis}, volume = {15}, number = {8}, pages = {101410}, year = {2025}, publisher = {Elsevier}, doi = {10.1016/j.jpha.2025.101410}, } - XMolCap: Advancing Molecular Captioning through Multimodal Fusion and Explainable Graph Neural NetworksDuong Thanh Tran , Nguyen Doan Hieu Nguyen , Nhat Truong Pham , Rajan Rakkiyappan , Rajendra Karki , and Balachandran Manavalan
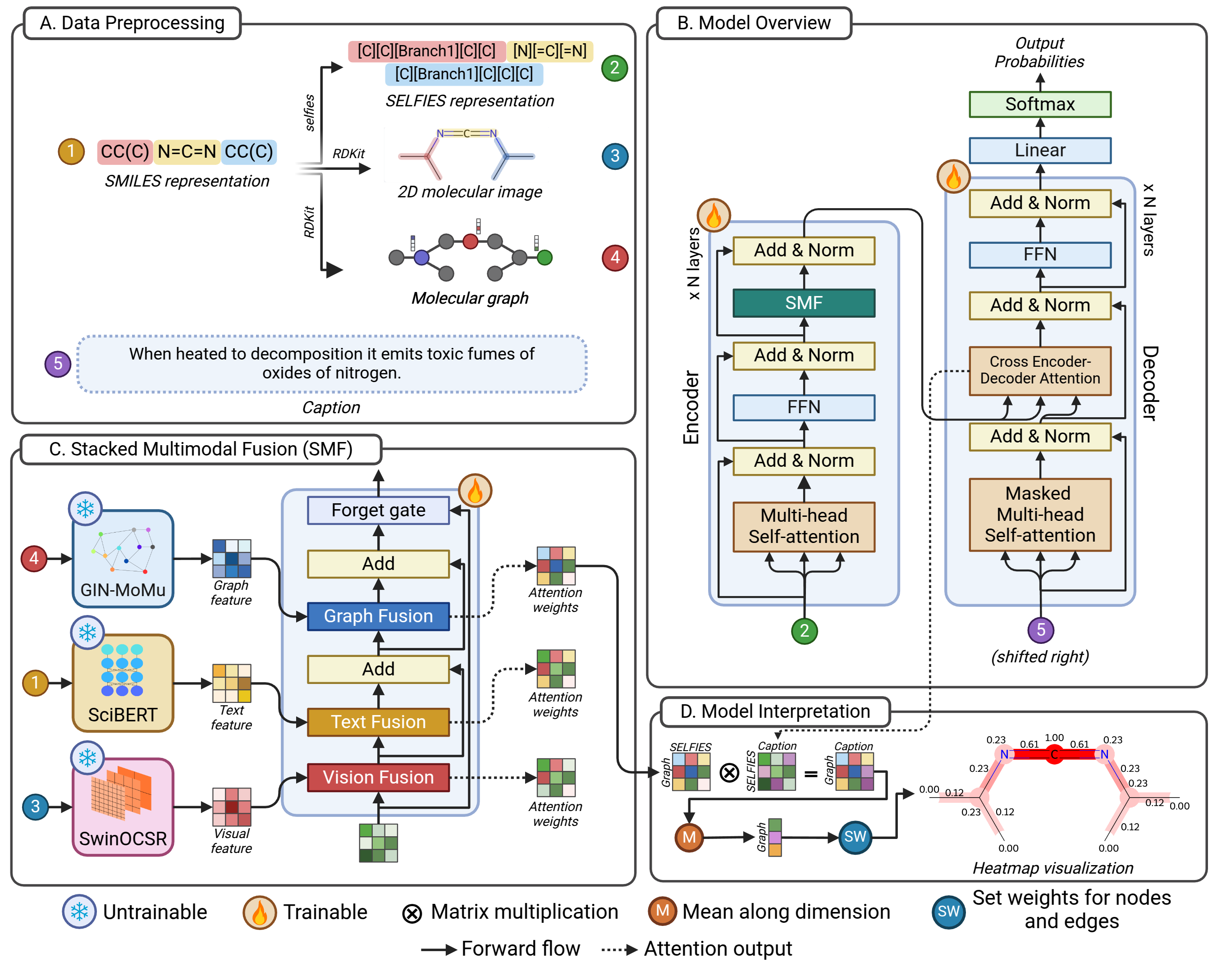
Large language models (LLMs) have significantly advanced computational biology by enabling the integration of molecular, protein, and natural language data to accelerate drug discovery. However, existing molecular captioning approaches often underutilize diverse molecular modalities and lack interpretability. In this study, we introduce XMolCap, a novel explainable molecular captioning framework that integrates molecular images, SMILES strings, and graph-based structures through a stacked multimodal fusion mechanism. The framework is built upon a BioT5-based encoder-decoder architecture, which serves as the backbone for extracting feature representations from SELFIES. By leveraging specialized models such as SwinOCSR, SciBERT, and GIN-MoMu, XMolCap effectively captures complementary information from each modality. Our model not only achieves state-of-the-art performance on two benchmark datasets (L+M-24 and ChEBI-20), outperforming several strong baselines, but also provides detailed, functional group-aware, and property-specific explanations through graph-based interpretation. XMolCap is publicly available at https://github.com/cbbl-skku-org/XMolCap/ for reproducibility and local deployment. We believe it holds strong potential for clinical and pharmaceutical applications by generating accurate, interpretable molecular descriptions that deepen our understanding of molecular properties and interactions.
@article{tran2025xmolcap, title = {XMolCap: Advancing Molecular Captioning through Multimodal Fusion and Explainable Graph Neural Networks}, author = {Tran, Duong Thanh and Nguyen, Nguyen Doan Hieu and Pham, Nhat Truong and Rakkiyappan, Rajan and Karki, Rajendra and Manavalan, Balachandran}, journal = {IEEE Journal of Biomedical and Health Informatics}, volume = {29}, number = {10}, pages = {7034--7045}, year = {2025}, publisher = {IEEE}, doi = {10.1109/JBHI.2025.3572910}, } - MemoCMT: multimodal emotion recognition using cross-modal transformer-based feature fusionScientific Reports, 2025
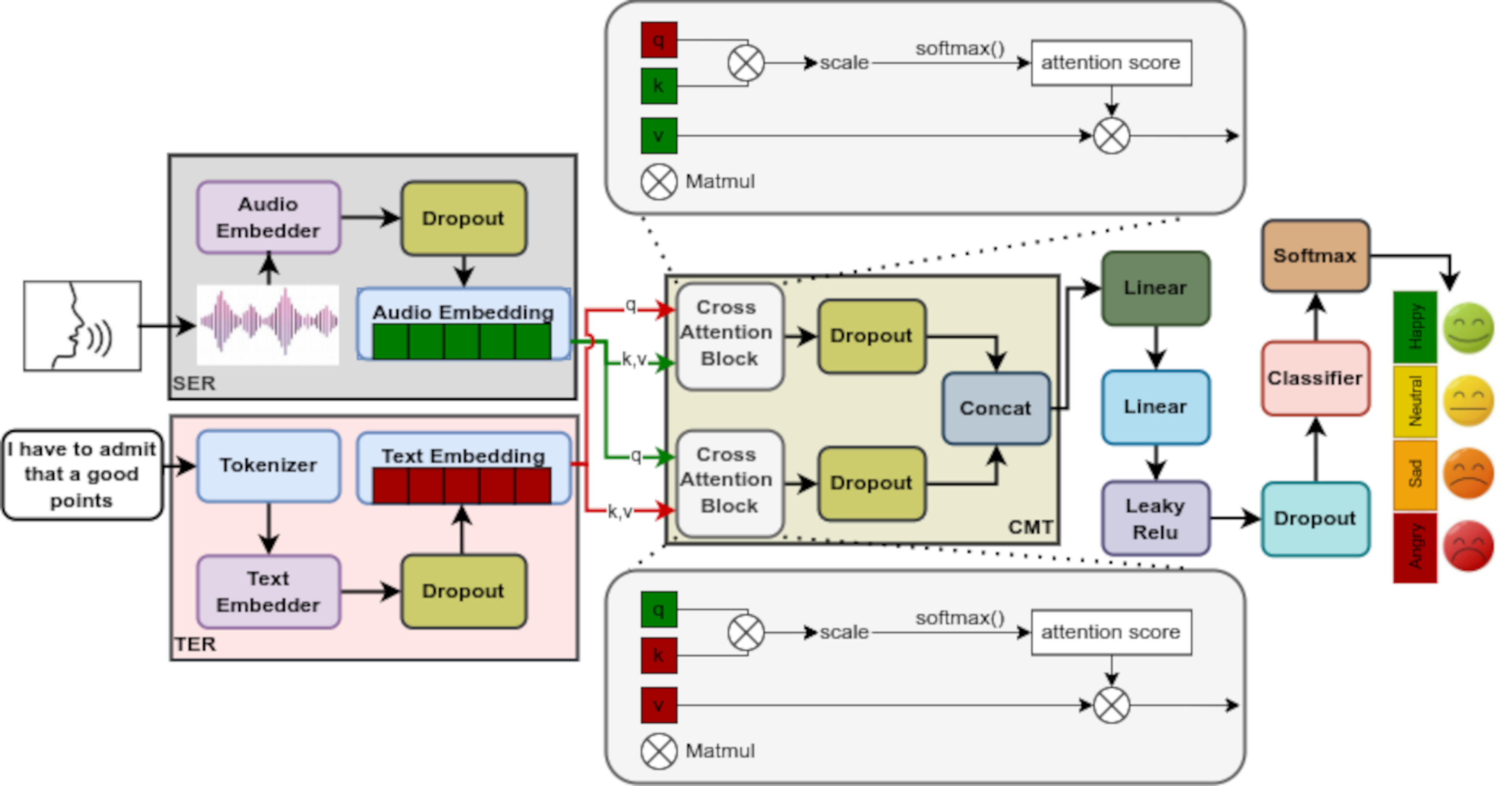
Speech emotion recognition has seen a surge in transformer models, which excel at understanding the overall message by analyzing long-term patterns in speech. However, these models come at a computational cost. In contrast, convolutional neural networks are faster but struggle with capturing these long-range relationships. Our proposed system, MemoCMT, tackles this challenge using a novel “cross-modal transformer” (CMT). This CMT can effectively analyze local and global speech features and their corresponding text. To boost efficiency, MemoCMT leverages recent advancements in pre-trained models: HuBERT extracts meaningful features from the audio, while BERT analyzes the text. The core innovation lies in how the CMT component utilizes and integrates these audio and text features. After this integration, different fusion techniques are applied before final emotion classification. Experiments show that MemoCMT achieves impressive performance, with the CMT using min aggregation achieving the highest unweighted accuracy (UW-Acc) of 81.33% and 91.93%, and weighted accuracy (W-Acc) of 81.85% and 91.84% respectively on benchmark IEMOCAP and ESD corpora. The results of our system demonstrate the generalization capacity and robustness for real-world industrial applications. Moreover, the implementation details of MemoCMT are publicly available at https://github.com/tpnam0901/MemoCMT/ for reproducibility purposes.
@article{khan2025memocmt, title = {MemoCMT: multimodal emotion recognition using cross-modal transformer-based feature fusion}, author = {Khan, Mustaqeem and Tran, Phuong-Nam and Pham, Nhat Truong and El Saddik, Abdulmotaleb and Othmani, Alice}, journal = {Scientific Reports}, volume = {15}, number = {1}, pages = {5473}, year = {2025}, publisher = {Nature Publishing Group UK London}, doi = {10.1038/s41598-025-89202-x}, } - DOGpred: A Novel Deep Learning Framework for Accurate Identification of Human O-linked Threonine Glycosylation SitesKi Wook Lee† , Nhat Truong Pham† , Hye Jung Min , Hyun Woo Park , Ji Won Lee , Han-En Lo , Na Young Kwon , Jimin Seo , Illia Shaginyan , Heeje Cho , Leyi Wei , Balachandran Manavalan , and Young-Jun Jeon
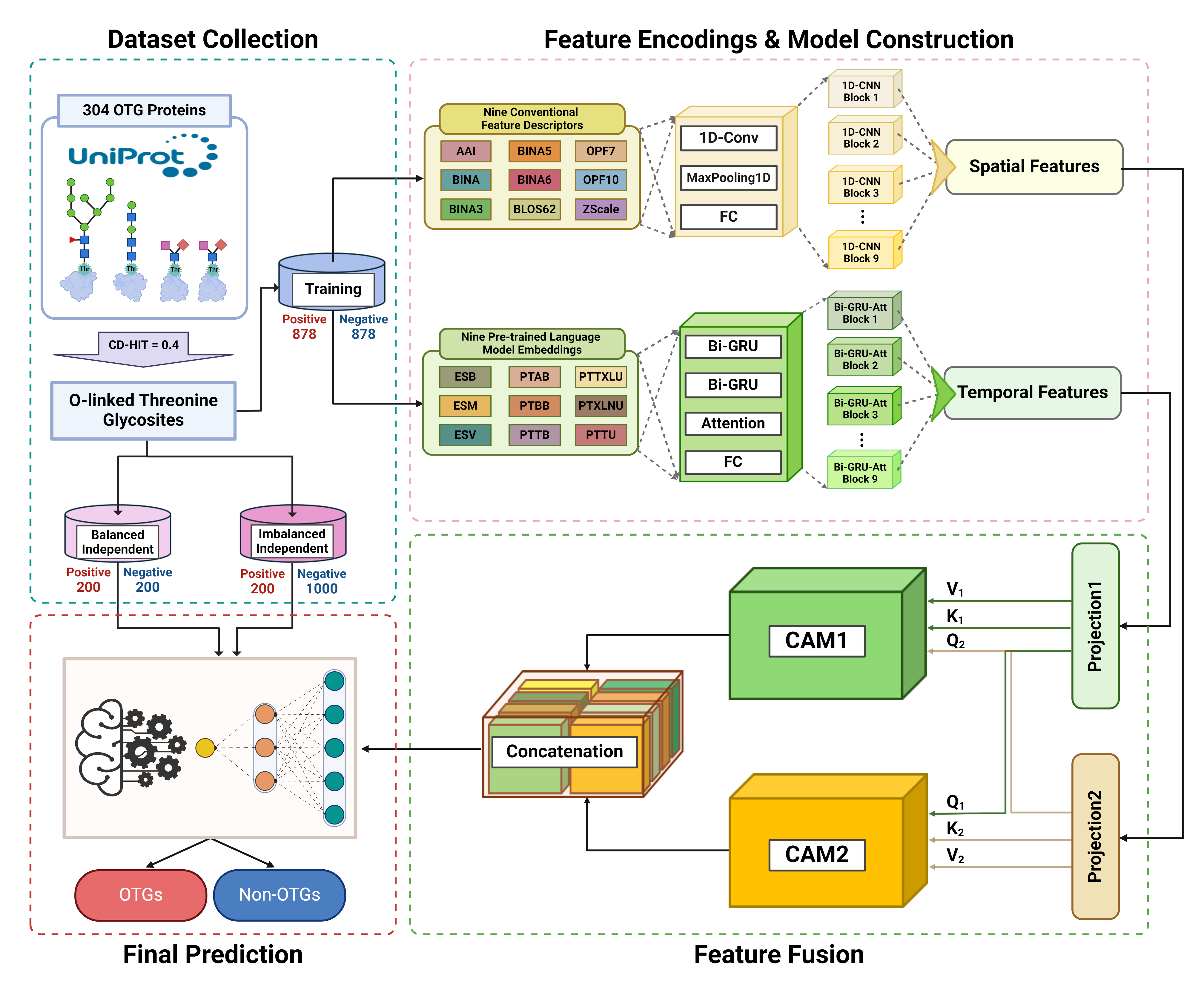
O-linked glycosylation is a crucial post-transcriptional modification that regulates protein function and biological processes. Dysregulation of this process is associated with various diseases, underscoring the need to accurately identify O-linked glycosylation sites on proteins. Current experimental methods for identifying O-linked threonine glycosylation (OTG) sites are often complex and costly. Consequently, developing computational tools that predict these sites based on protein features is crucial. Such tools can complement experimental approaches, enhancing our understanding of the role of OTG dysregulation in diseases and uncovering potential therapeutic targets. In this study, we developed DOGpred, a deep learning-based predictor for precisely identifying human OTGs using high-latent feature representations. Initially, we extracted nine different conventional feature descriptors (CFDs) and nine pre-trained protein language model (PLM)-based embeddings. Notably, each feature was encoded as a 2D tensor, capturing both the sequential and inherent feature characteristics. Subsequently, we designed a stacked convolutional neural network (CNN) module to learn spatial feature representations from CFDs and a stacked recurrent neural network (RNN) module to learn temporal feature representations from PLM-based embeddings. These features were integrated using attention-based fusion mechanisms to generate high-level feature representations for final classification. Ablation analysis and independent tests demonstrated that the optimal model (DOGpred), employing a stacked 1D CNN and a stacked attention-based RNN module with cross-attention feature fusion, achieved the best performance on the training dataset and significantly outperformed machine learning-based single-feature models and state-of-the-art methods on independent datasets. Furthermore, DOGpred is publicly available at https://github.com/JeonRPM/DOGpred/ for free access and usage.
@article{lee2025dogpred, title = {DOGpred: A Novel Deep Learning Framework for Accurate Identification of Human O-linked Threonine Glycosylation Sites}, author = {Lee, Ki Wook and Pham, Nhat Truong and Min, Hye Jung and Park, Hyun Woo and Lee, Ji Won and Lo, Han-En and Kwon, Na Young and Seo, Jimin and Shaginyan, Illia and Cho, Heeje and Wei, Leyi and Manavalan, Balachandran and Jeon, Young-Jun}, journal = {Journal of Molecular Biology}, volume = {437}, number = {6}, pages = {168977}, year = {2025}, publisher = {Elsevier}, doi = {10.1016/j.jmb.2025.168977}, } - Leveraging deep transfer learning and explainable AI for accurate COVID-19 diagnosis: Insights from a multi-national chest CT scan studyNhat Truong Pham , Jinsol Ko , Masaud Shah , Rajan Rakkiyappan , Hyun Goo Woo , and Balachandran Manavalan
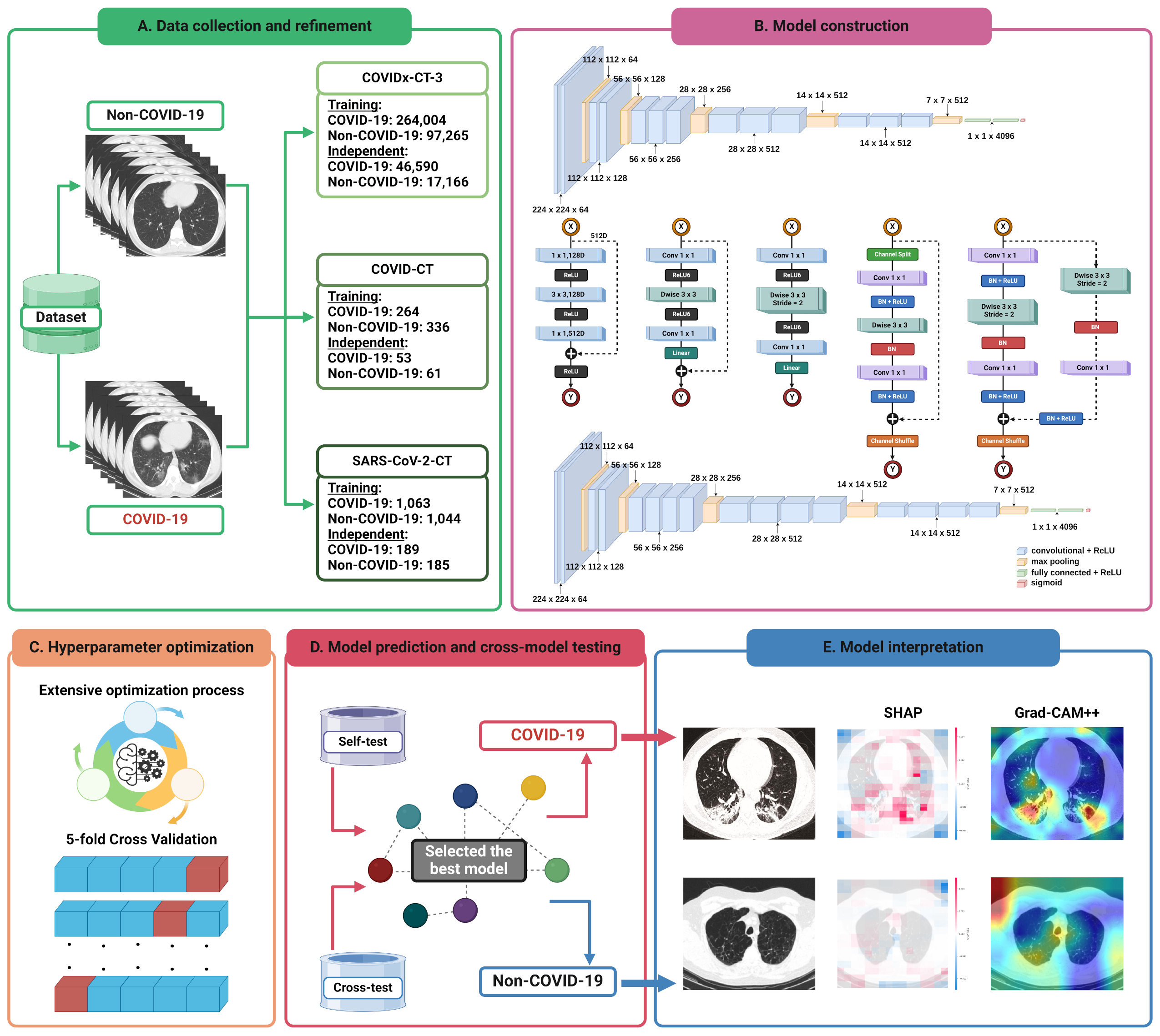
The COVID-19 pandemic has emerged as a global health crisis, impacting millions worldwide. Although chest computed tomography (CT) scan images are pivotal in diagnosing COVID-19, their manual interpretation by radiologists is time-consuming and potentially subjective. Automated computer-aided diagnostic (CAD) frameworks offer efficient and objective solutions. However, machine or deep learning methods often face challenges in their reproducibility due to underlying biases and methodological flaws. To address these issues, we propose XCT-COVID, an explainable, transferable, and reproducible CAD framework based on deep transfer learning to predict COVID-19 infection from CT scan images accurately. This is the first study to develop three distinct models within a unified framework by leveraging a previously unexplored large dataset and two widely used smaller datasets. We employed five known convolutional neural network architectures, both with and without pretrained weights, on the larger dataset. We optimized hyperparameters through extensive grid search and 5-fold cross-validation (CV), significantly enhancing the model performance. Experimental results from the larger dataset showed that the VGG16 architecture (XCT-COVID-L) with pretrained weights consistently outperformed other architectures, achieving the best performance, on both 5-fold CV and independent test. When evaluated with the external datasets, XCT-COVID-L performed well with data with similar distributions, demonstrating its transferability. However, its performance significantly decreased on smaller datasets with lower-quality images. To address this, we developed other models, XCT-COVID-S1 and XCT-COVID-S2, specifically for the smaller datasets, outperforming existing methods. Moreover, eXplainable Artificial Intelligence (XAI) analyses were employed to interpret the models’ functionalities. For prediction and reproducibility purposes, the implementation of XCT-COVID is publicly accessible at https://github.com/cbbl-skku-org/XCT-COVID/.
@article{pham2025leveraging, title = {Leveraging deep transfer learning and explainable AI for accurate COVID-19 diagnosis: Insights from a multi-national chest CT scan study}, author = {Pham, Nhat Truong and Ko, Jinsol and Shah, Masaud and Rakkiyappan, Rajan and Woo, Hyun Goo and Manavalan, Balachandran}, journal = {Computers in Biology and Medicine}, volume = {185}, pages = {109461}, year = {2025}, publisher = {Elsevier}, doi = {10.1016/j.compbiomed.2024.109461}, } - MST-m6A: A Novel Multi-Scale Transformer-based Framework for Accurate Prediction of m6A Modification Sites Across Diverse Cellular ContextsQiaosen Su , Le Thi Phan , Nhat Truong Pham , Leyi Wei , and Balachandran Manavalan
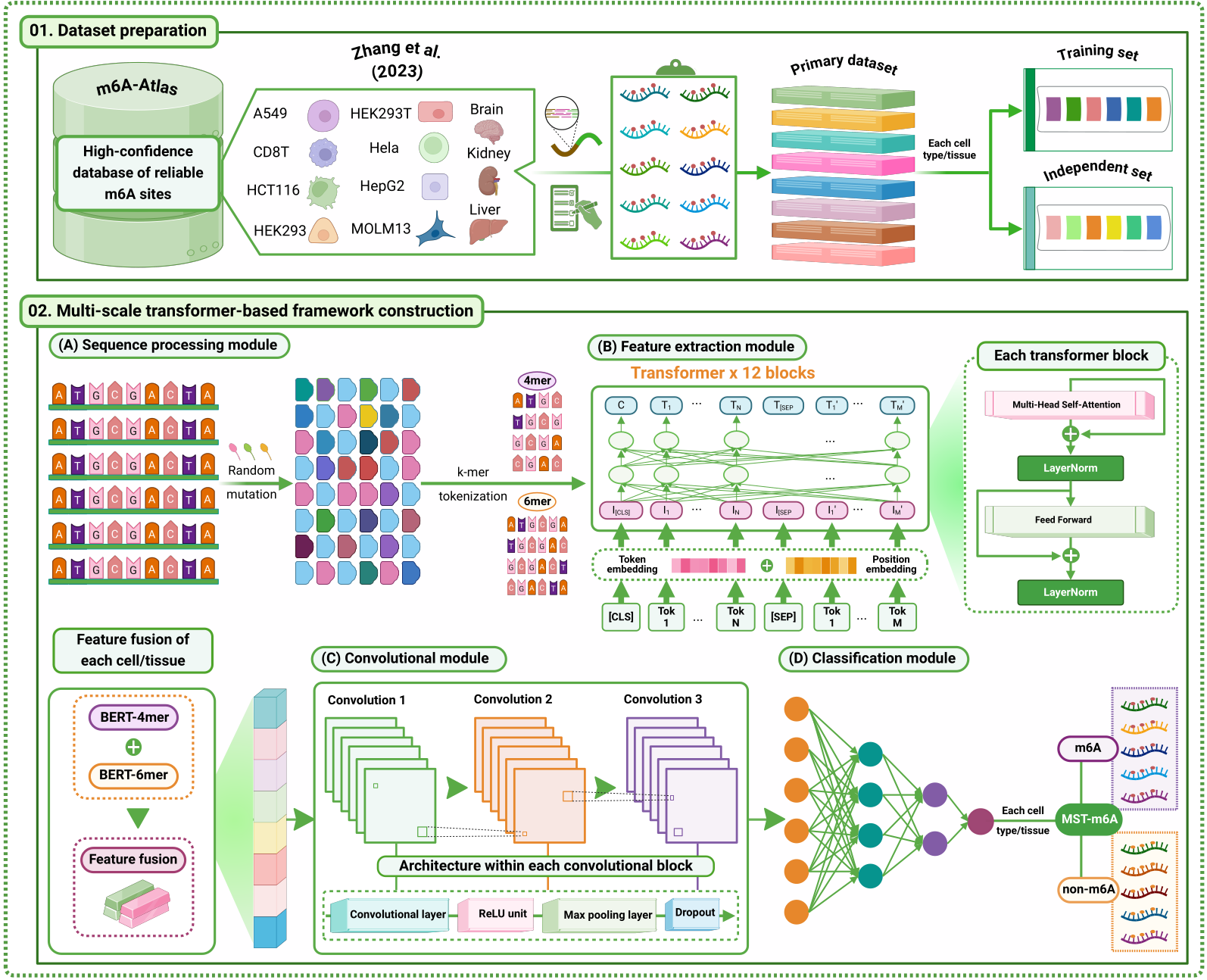
N6-methyladenosine (m6A) modification, a prevalent epigenetic mark in eukaryotic cells, is crucial in regulating gene expression and RNA metabolism. Accurately identifying m6A modification sites is essential for understanding their functions within biological processes and the intricate mechanisms that regulate them. Recent advances in high-throughput sequencing technologies have enabled the generation of extensive datasets characterizing m6A modification sites at single-nucleotide resolution, leading to the development of computational methods for identifying m6A RNA modification sites. However, most current methods focus on specific cell lines, limiting their generalizability and practical application across diverse biological contexts. To address the limitation, we propose MST-m6A, a novel approach for identifying m6A modification sites with higher accuracy across various cell lines and tissues. MST-m6A utilizes a multi-scale transformer-based architecture, employing dual k-mer tokenization to capture rich feature representations and global contextual information from RNA sequences at multiple levels of granularity. These representations are then effectively combined using a channel fusion mechanism and further processed by a convolutional neural network to enhance prediction accuracy. Rigorous validation demonstrates that MST-m6A significantly outperforms conventional machine learning models, deep learning models, and state-of-the-art predictors. We anticipate that the high precision and cross-cell-type adaptability of MST-m6A will provide valuable insights into m6A biology and facilitate advancements in related fields. The proposed approach is available at https://github.com/cbbl-skku-org/MST-m6A/ for prediction and reproducibility purposes.
@article{su2024mst, title = {MST-m6A: A Novel Multi-Scale Transformer-based Framework for Accurate Prediction of m6A Modification Sites Across Diverse Cellular Contexts}, author = {Su, Qiaosen and Phan, Le Thi and Pham, Nhat Truong and Wei, Leyi and Manavalan, Balachandran}, journal = {Journal of Molecular Biology}, volume = {437}, number = {6}, pages = {168856}, year = {2025}, publisher = {Elsevier}, doi = {10.1016/j.jmb.2024.168856}, }

2024
- HuBERT-CLAP: Contrastive Learning-Based Multimodal Emotion Recognition using Self-Alignment Approach
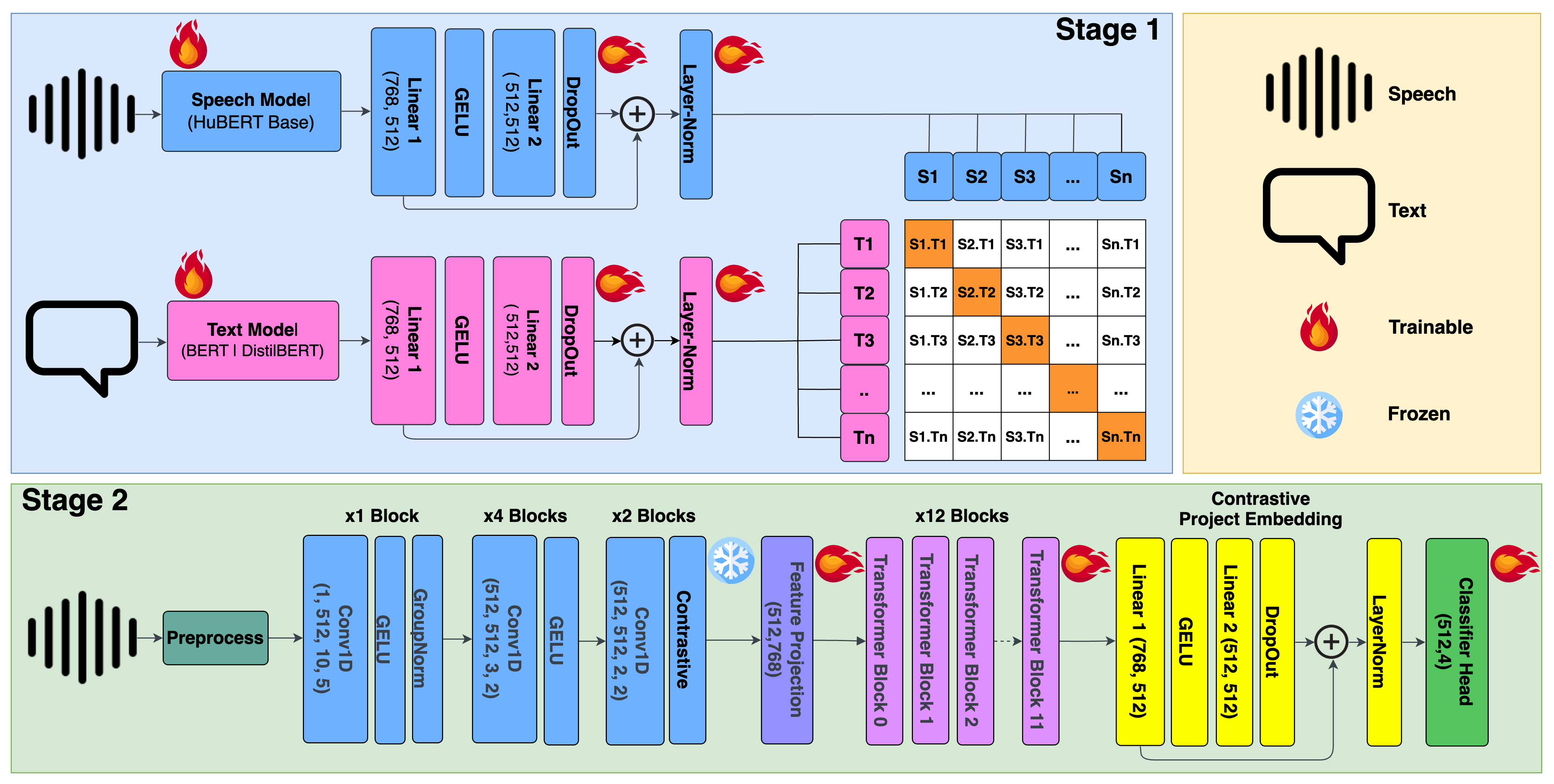
A breakthrough in deep learning has led to improvements in speech emotion recognition (SER), but these studies tend to process fixed-length segments, resulting in degraded performance. Therefore, multimodal approaches that combine audio and text features improve SER but lack modality alignment. In this study, we introduce HuBERT-CLAP, a contrastive language-audio self-alignment pre-training framework for SER to address the aforementioned issue. Initially, we employ CLIP to train a contrastive self-alignment model using HuBERT for audio and BERT/DistilBERT for text to extract discriminative cues from the input sequences and map informative features from text to audio features. Additionally, HuBERT in the pre-trained HuBERT-CLAP undergoes partial fine-tuning to enhance the effectiveness in predicting emotional states. Furthermore, we evaluated our model on the IEMOCAP dataset, where it outperformed the non-pre-training model, achieving a weighted accuracy of 77.22%. Our source code is publicly available at https://github.com/oggyfaker/HuBERT-CLAP/ for reproducible purposes.
@inproceedings{nguyen2024hubert, title = {HuBERT-CLAP: Contrastive Learning-Based Multimodal Emotion Recognition using Self-Alignment Approach}, author = {Nguyen, Long H. and Pham, Nhat Truong and Khan, Mustaqeem and Othmani, Alice and El Saddik, Abdulmotaleb}, booktitle = {Proceedings of the 6th ACM International Conference on Multimedia in Asia}, pages = {1--6}, year = {2024}, doi = {10.1145/3696409.3700183}, } - Federated Learning with U-Net for Brain Tumor Segmentation: Impact of Client Numbers and Data DistributionThu Thuy Le , Nhat Truong Pham , Phuong-Nam Tran , and Duc Ngoc Minh DangIn 2024 15th International Conference on Information and Communication Technology Convergence (ICTC), 2024
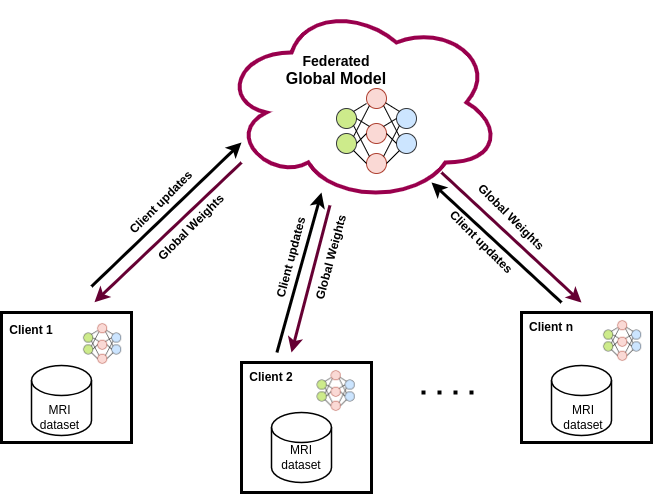
Brain tumor segmentation plays a crucial role in diagnosis and treatment planning. However, sharing patient data for training deep learning models raises privacy concerns. In this paper, we propose a federated learning (FL) approach that utilizes a U-Net architecture for brain tumor segmentation. We evaluate the performance of federated U-Net models across different data distribution scenarios and varying numbers of clients. Specifically, we compare the effectiveness of two FL methods: Federated Averaging (FedAvg) and Federated Stochastic Gradient Descent (FedSGD). Through experiments conducted on the BraTS dataset, we observe that as the number of clients increases, the overall performance of the models tends to decrease. Moreover, we find that skewed data distribution often outperforms equal data division. Additionally, we consistently observe that FedAvg yields superior results compared to FedSGD. Our proposed approach enables hospitals to collaboratively train models on their local data without directly sharing sensitive information. This preserves patient privacy while ensuring accurate tumor segmentation. The results of our study underscore the significance of strategic data distribution in FL environments and provide valuable insights for optimizing FL strategies in medical imaging applications.
@inproceedings{le2024federated, title = {Federated Learning with U-Net for Brain Tumor Segmentation: Impact of Client Numbers and Data Distribution}, author = {Le, Thu Thuy and Pham, Nhat Truong and Tran, Phuong-Nam and Dang, Duc Ngoc Minh}, booktitle = {2024 15th International Conference on Information and Communication Technology Convergence ICTC}, pages = {2048--2053}, year = {2024}, organization = {IEEE}, doi = {10.1109/ICTC62082.2024.10826674}, } - Towards Real-time Vietnamese Traffic Sign Recognition on Embedded SystemsPhuong-Nam Tran , Nhat Truong Pham , Nam Pham Van Hai , Duc Tai Phan , Tuan Cuong Nguyen , and Duc Ngoc Minh DangIn 2024 15th International Conference on Information and Communication Technology Convergence (ICTC), 2024
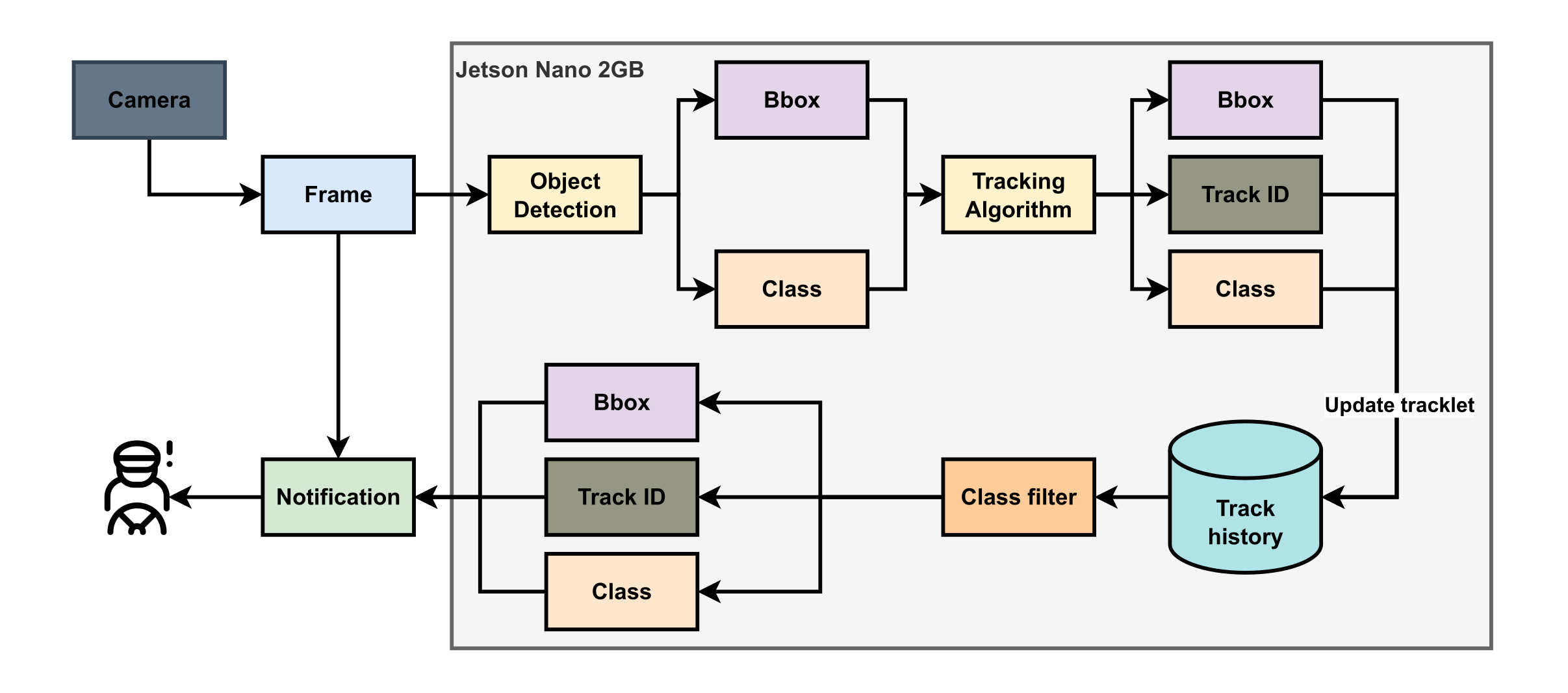
In recent years, AI development has brought many significant changes in various aspects of our daily lives. Integrating AI technology into various applications has revolutionized multiple domains, and one particularly vital area is traffic sign recognition, which significantly enhances driver safety. This paper presents an approach to traffic sign recognition specifically designed for the Jetson Nano 2GB device. By utilizing the YOLOv8 Nano model, the proposed approach achieves a remarkable frame rate of up to 32 frames per second (FPS). To optimize inference speed on Jetson with limited memory, the approach incorporates TensorRT and quantization techniques. In addition, this paper introduces a dataset called the Vietnamese Traffic Sign Detection Database 100 (VTSDB100). This dataset is an extension of the VTSDB46 dataset and encompasses a comprehensive collection of 100 different classes of traffic signs. These signs were captured in diverse locations within Ho Chi Minh City, Vietnam, providing a rich and diverse dataset for training and evaluating traffic sign recognition models. An extensive experiment and analysis are also conducted using various object detection methods on the VTSDB100 dataset. The findings highlight the potential of deploying the proposed approach on resource-constrained devices and provide valuable insights for further research and development in the field of AI-powered driver safety systems.
@inproceedings{tran2024towards, title = {Towards Real-time Vietnamese Traffic Sign Recognition on Embedded Systems}, author = {Tran, Phuong-Nam and Pham, Nhat Truong and Pham Van Hai, Nam and Phan, Duc Tai and Nguyen, Tuan Cuong and Dang, Duc Ngoc Minh}, booktitle = {2024 15th International Conference on Information and Communication Technology Convergence ICTC}, pages = {1--6}, year = {2024}, organization = {IEEE}, doi = {10.1109/ICTC62082.2024.10827558}, } - Mol2Lang-VLM: Vision- and Text-Guided Generative Pre-trained Language Models for Advancing Molecule Captioning through Multimodal Fusion
This paper introduces Mol2Lang-VLM, an enhanced method for refining generative pre-trained language models for molecule captioning using multimodal features to achieve more accurate caption generation. Our approach leverages the encoder and decoder blocks of the Transformer-based architecture by introducing third sub-layers into both. Specifically, we insert sub-layers in the encoder to fuse features from SELFIES strings and molecular images, while the decoder fuses features from SMILES strings and their corresponding descriptions. Moreover, cross multi-head attention is employed instead of common multi-head attention to enable the decoder to attend to the encoder’s output, thereby integrating the encoded contextual information for better and more accurate caption generation. Performance evaluation on the CheBI-20 and L+M-24 benchmark datasets demonstrates Mol2Lang-VLM’s superiority, achieving higher accuracy and quality in caption generation compared to existing methods. Our code and pre-processed data are available at https://github.com/nhattruongpham/mol-lang-bridge/tree/mol2lang/.
@inproceedings{tran2024mollangvlm, title = {Mol2Lang-{VLM}: Vision- and Text-Guided Generative Pre-trained Language Models for Advancing Molecule Captioning through Multimodal Fusion}, author = {Tran, Duong Thanh and Pham, Nhat Truong and Nguyen, Nguyen Doan Hieu and Manavalan, Balachandran}, booktitle = {Proceedings of the 1st Workshop on Language + Molecules L+M 2024}, pages = {97--102}, year = {2024}, doi = {10.18653/v1/2024.langmol-1.12}, } - Lang2Mol-Diff: A Diffusion-Based Generative Model for Language-to-Molecule Translation Leveraging SELFIES Molecular String Representation
Generating de novo molecules from textual descriptions is challenging due to potential issues with molecule validity in SMILES representation and limitations of autoregressive models. This work introduces Lang2Mol-Diff, a diffusion-based language-to-molecule generative model using the SELFIES representation. Specifically, Lang2Mol-Diff leverages the strengths of two state-of-the-art molecular generative models: BioT5 and TGM-DLM. By employing BioT5 to tokenize the SELFIES representation, Lang2Mol-Diff addresses the validity issues associated with SMILES strings. Additionally, it incorporates a text diffusion mechanism from TGM-DLM to overcome the limitations of autoregressive models in this domain. To the best of our knowledge, this is the first study to leverage the diffusion mechanism for text-based de novo molecule generation using the SELFIES molecular string representation. Performance evaluation on the L+M-24 benchmark dataset shows that Lang2Mol-Diff outperforms all existing methods for molecule generation in terms of validity. Our code and pre-processed data are available at https://github.com/nhattruongpham/mol-lang-bridge/tree/lang2mol/.
@inproceedings{nguyen2024langmoldiff, title = {Lang2Mol-Diff: A Diffusion-Based Generative Model for Language-to-Molecule Translation Leveraging SELFIES Molecular String Representation}, author = {Nguyen, Nguyen Doan Hieu and Pham, Nhat Truong and Tran, Duong Thanh and Manavalan, Balachandran}, booktitle = {Proceedings of the 1st Workshop on Language + Molecules L+M 2024}, pages = {128--134}, year = {2024}, doi = {10.18653/v1/2024.langmol-1.15}, } - HOTGpred: Enhancing human O-linked threonine glycosylation prediction using integrated pretrained protein language model-based features and multi-stage feature selection approachNhat Truong Pham† , Ying Zhang† , Rajan Rakkiyappan , and Balachandran Manavalan
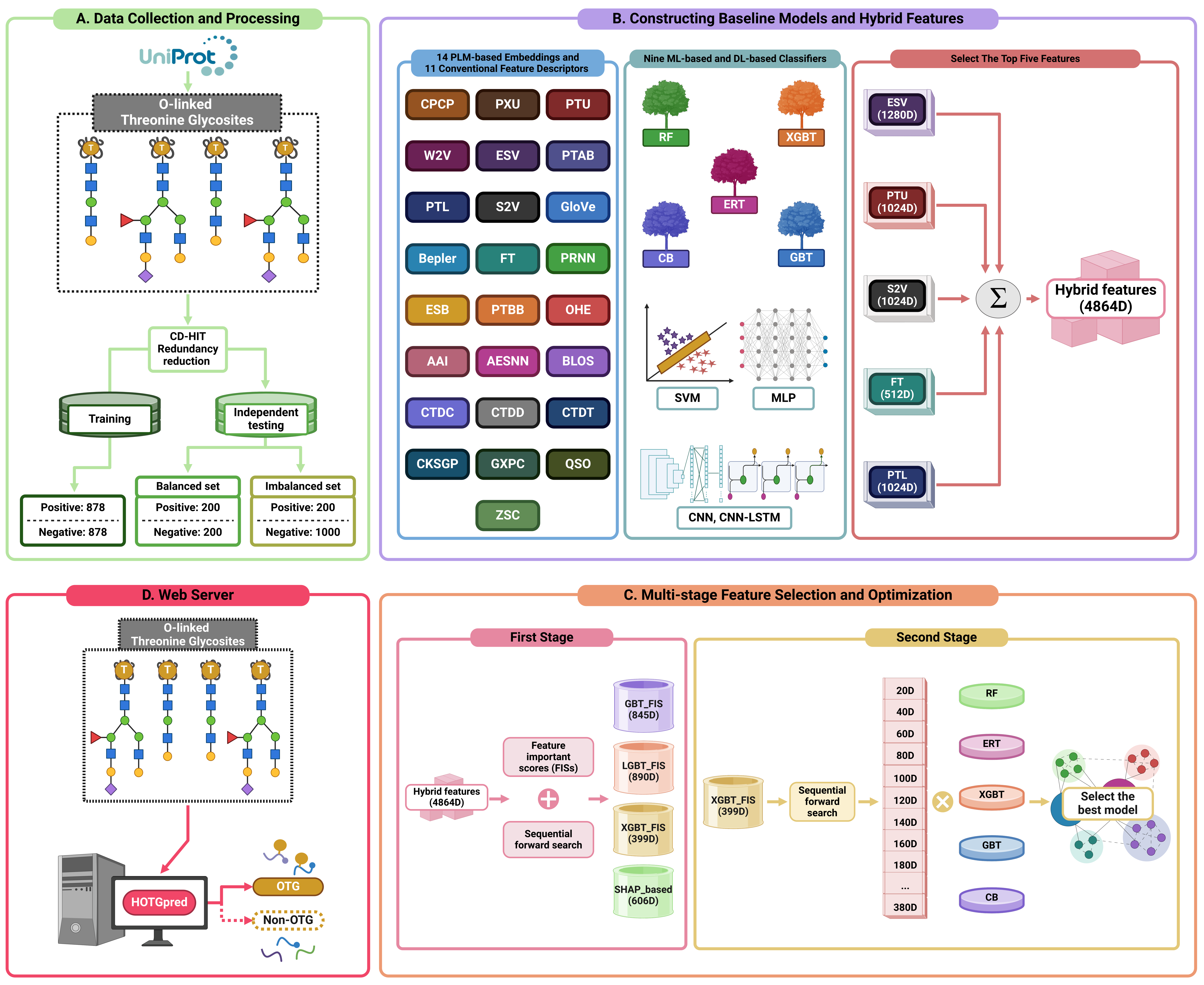
O-linked glycosylation is a complex post-translational modification (PTM) in human proteins that plays a critical role in regulating various cellular metabolic and signaling pathways. In contrast to N-linked glycosylation, O-linked glycosylation lacks specific sequence features and maintains an unstable core structure. Identifying O-linked threonine glycosylation sites (OTGs) remains challenging, requiring extensive experimental tests. While bioinformatics tools have emerged for predicting OTGs, their reliance on limited conventional features and absence of well-defined feature selection strategies limit their effectiveness. To address these limitations, we introduced HOTGpred (Human O-linked Threonine Glycosylation predictor), employing a multi-stage feature selection process to identify the optimal feature set for accurately identifying OTGs. Initially, we assessed 25 different feature sets derived from various pretrained protein language model (PLM)-based embeddings and conventional feature descriptors using nine classifiers. Subsequently, we integrated the top five embeddings linearly and determined the most effective scoring function for ranking hybrid features, identifying the optimal feature set through a process of sequential forward search. Among the classifiers, the extreme gradient boosting (XGBT)-based model, using the optimal feature set (HOTGpred), achieved 92.03% accuracy on the training dataset and 88.25% on the balanced independent dataset. Notably, HOTGpred significantly outperformed the current state-of-the-art methods on both the balanced and imbalanced independent datasets, demonstrating its superior prediction capabilities. Additionally, SHapley Additive exPlanations (SHAP) and ablation analyses were conducted to identify the features contributing most significantly to HOTGpred. Finally, we developed an easy-to-navigate web server, accessible at https://balalab-skku.org/HOTGpred/, to support glycobiologists in their research on glycosylation structure and function.
@article{pham2024hotgpred, title = {HOTGpred: Enhancing human O-linked threonine glycosylation prediction using integrated pretrained protein language model-based features and multi-stage feature selection approach}, author = {Pham, Nhat Truong and Zhang, Ying and Rakkiyappan, Rajan and Manavalan, Balachandran}, journal = {Computers in Biology and Medicine}, volume = {179}, pages = {108859}, year = {2024}, publisher = {Elsevier}, doi = {10.1016/j.compbiomed.2024.108859}, } - mACPpred 2.0: Stacked Deep Learning for Anticancer Peptide Prediction with Integrated Spatial and Probabilistic Feature RepresentationsVinoth Kumar Sangaraju† , Nhat Truong Pham† , Leyi Wei , Xue Yu , and Balachandran Manavalan
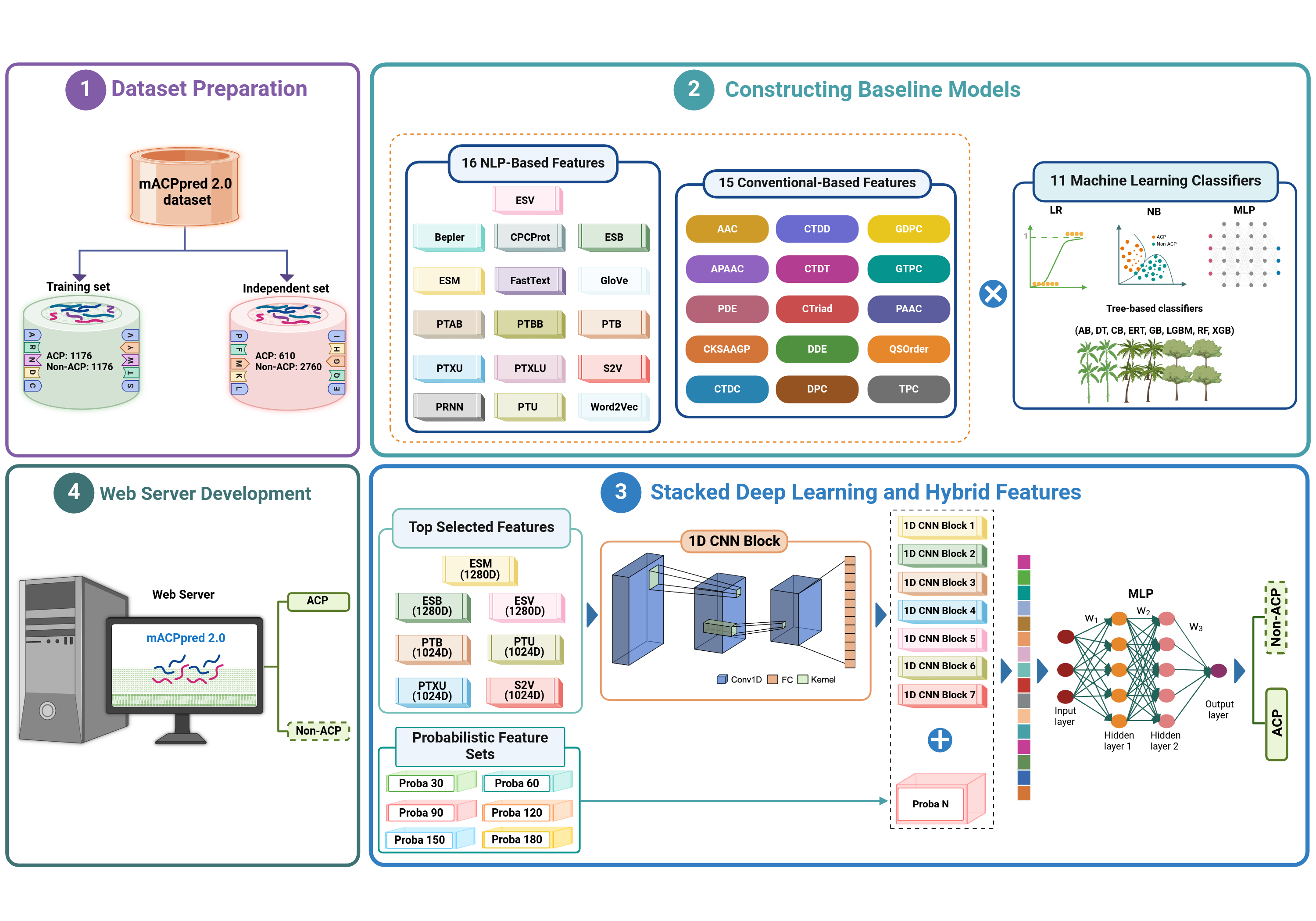
Anticancer peptides (ACPs), naturally occurring molecules with remarkable potential to target and kill cancer cells. However, identifying ACPs based solely from their primary amino acid sequences remains a major hurdle in immunoinformatics. In the past, several web-based machine learning (ML) tools have been proposed to assist researchers in identifying potential ACPs for further testing. Notably, our meta-approach method, mACPpred, introduced in 2019, has significantly advanced the field of ACP research. Given the exponential growth in the number of characterized ACPs, there is now a pressing need to create an updated version of mACPpred. To develop mACPpred 2.0, we constructed an up-to-date benchmarking dataset by integrating all publicly available ACP datasets. We employed a large-scale of feature descriptors, encompassing both conventional feature descriptors and advanced pre-trained natural language processing (NLP)-based embeddings. We evaluated their ability to discriminate between ACPs and non-ACPs using eleven different classifiers. Subsequently, we employed a stacked deep learning (SDL) approach, incorporating 1D convolutional neural network (1D CNN) blocks and hybrid features. These features included the top seven performing NLP-based features and 90 probabilistic features, allowing us to identify hidden patterns within these diverse features and improve the accuracy of our ACP prediction model. This is the first study to integrate spatial and probabilistic feature representations for predicting ACPs. Rigorous cross-validation and independent tests conclusively demonstrated that mACPpred 2.0 not only surpassed its predecessor (mACPpred) but also outperformed the existing state-of-the-art predictors, highlighting the importance of advanced feature representation capabilities attained through SDL. To facilitate widespread use and accessibility, we have developed a user-friendly for mACPpred 2.0, available at https://balalab-skku.org/mACPpred2/.
@article{sangaraju2024macppred, title = {mACPpred 2.0: Stacked Deep Learning for Anticancer Peptide Prediction with Integrated Spatial and Probabilistic Feature Representations}, author = {Sangaraju, Vinoth Kumar and Pham, Nhat Truong and Wei, Leyi and Yu, Xue and Manavalan, Balachandran}, journal = {Journal of Molecular Biology}, volume = {436}, number = {17}, pages = {168687}, year = {2024}, publisher = {Elsevier}, doi = {10.1016/j.jmb.2024.168687}, } - SEP-AlgPro: An efficient allergen prediction tool utilizing traditional machine learning and deep learning techniques with protein language model featuresShaherin Basith , Nhat Truong Pham , Balachandran Manavalan , and Gwang Lee
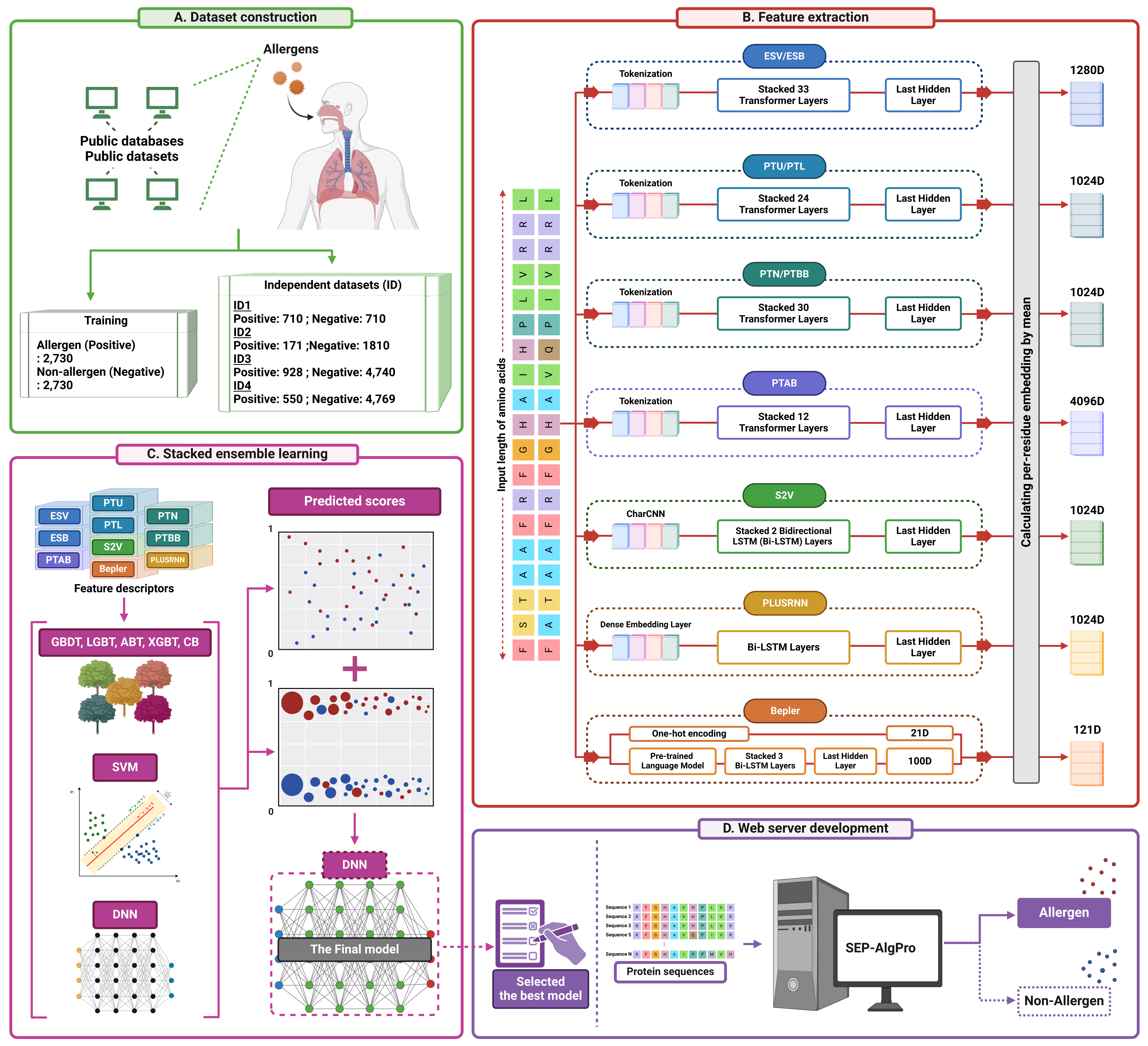
Allergy is a hypersensitive condition in which individuals develop objective symptoms when exposed to harmless substances at a dose that would cause no harm to a “normal” person. Most current computational methods for allergen identification rely on homology or conventional machine learning using limited set of feature descriptors or validation on specific datasets, making them inefficient and inaccurate. Here, we propose SEP-AlgPro for the accurate identification of allergen protein from sequence information. We analyzed 10 conventional protein-based features and 14 different features derived from protein language models to gauge their effectiveness in differentiating allergens from non-allergens using 15 different classifiers. However, the final optimized model employs top 10 feature descriptors with top seven machine learning classifiers. Results show that the features derived from protein language models exhibit superior discriminative capabilities compared to traditional feature sets. This enabled us to select the most discriminatory baseline models, whose predicted outputs were aggregated and used as input to a deep neural network for the final allergen prediction. Extensive case studies showed that SEP-AlgPro outperforms state-of-the-art predictors in accurately identifying allergens. A user-friendly web server was developed and made freely available at https://balalab-skku.org/SEP-AlgPro/, making it a powerful tool for identifying potential allergens.
@article{basith2024sep, title = {SEP-AlgPro: An efficient allergen prediction tool utilizing traditional machine learning and deep learning techniques with protein language model features}, author = {Basith, Shaherin and Pham, Nhat Truong and Manavalan, Balachandran and Lee, Gwang}, journal = {International Journal of Biological Macromolecules}, volume = {273}, pages = {133085}, year = {2024}, publisher = {Elsevier}, doi = {10.1016/j.ijbiomac.2024.133085}, } - Meta-2OM: A multi-classifier meta-model for the accurate prediction of RNA 2’-O-methylation sites in human RNAMd Harun-Or-Roshid , Nhat Truong Pham , Balachandran Manavalan , and Hiroyuki KurataPLOS One, 2024
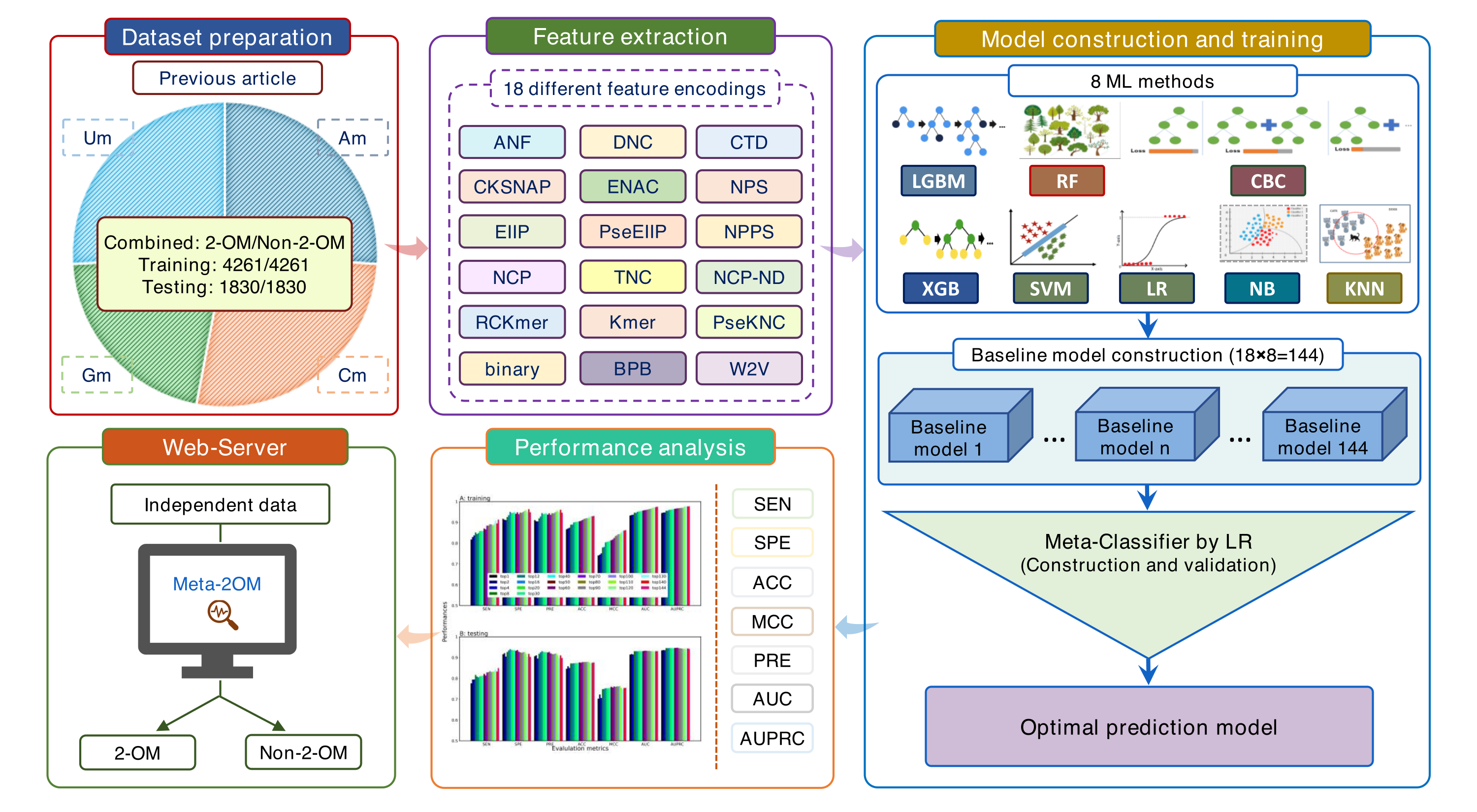
2’-O-methylation (2-OM or Nm) is a widespread RNA modification observed in various RNA types like tRNA, mRNA, rRNA, miRNA, piRNA, and snRNA, which plays a crucial role in several biological functional mechanisms and innate immunity. To comprehend its modification mechanisms and potential epigenetic regulation, it is necessary to accurately identify 2-OM sites. However, biological experiments can be tedious, time-consuming, and expensive. Furthermore, currently available computational methods face challenges due to inadequate datasets and limited classification capabilities. To address these challenges, we proposed Meta-2OM, a cutting-edge predictor that can accurately identify 2-OM sites in human RNA. In brief, we applied a meta-learning approach that considered eight conventional machine learning algorithms, including tree-based classifiers and decision boundary-based classifiers, and eighteen different feature encoding algorithms that cover physicochemical, compositional, position-specific and natural language processing information. The predicted probabilities of 2-OM sites from the baseline models are then combined and trained using logistic regression to generate the final prediction. Consequently, Meta-2OM achieved excellent performance in both 5-fold cross-validation training and independent testing, outperforming all existing state-of-the-art methods. Specifically, on the independent test set, Meta-2OM achieved an overall accuracy of 0.870, sensitivity of 0.836, specificity of 0.904, and Matthews correlation coefficient of 0.743. To facilitate its use, a user-friendly web server and standalone program have been developed and freely available at http://kurata35.bio.kyutech.ac.jp/Meta-2OM/ and https://github.com/kuratahiroyuki/Meta-2OM/.
@article{harun2024meta, title = {Meta-2OM: A multi-classifier meta-model for the accurate prediction of RNA 2'-O-methylation sites in human RNA}, author = {Harun-Or-Roshid, Md and Pham, Nhat Truong and Manavalan, Balachandran and Kurata, Hiroyuki}, journal = {PLOS One}, volume = {19}, number = {6}, pages = {e0305406}, year = {2024}, publisher = {Public Library of Science San Francisco, CA USA}, doi = {10.1371/journal.pone.0305406}, } - ac4C-AFL: A high-precision identification of human mRNA N4-acetylcytidine sites based on adaptive feature representation learningNhat Truong Pham , Annie Terrina Terrance , Young-Jun Jeon , Rajan Rakkiyappan , and Balachandran Manavalan
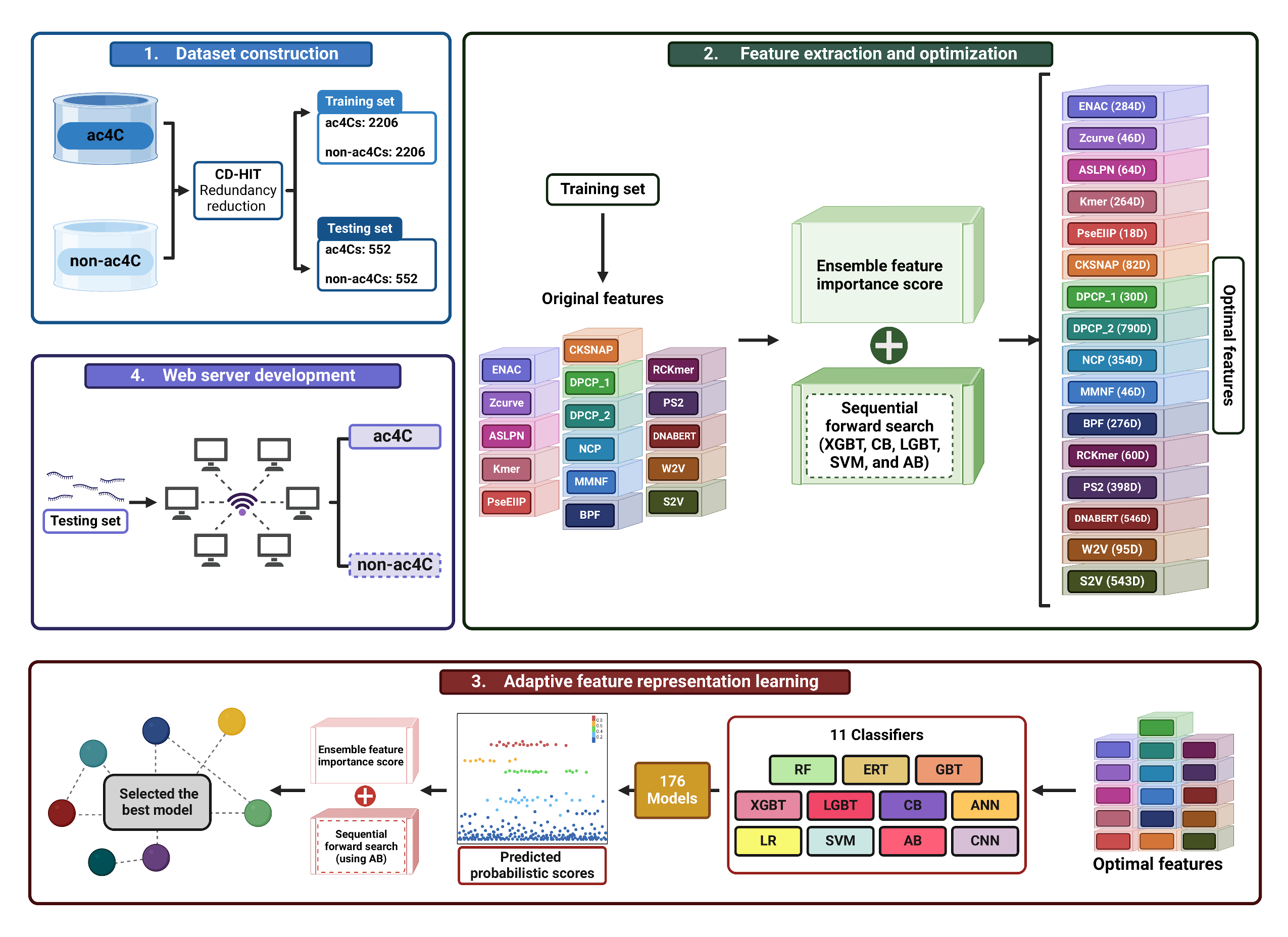
RNA N4-acetylcytidine (ac4C) is a highly conserved RNA modification that plays a crucial role in controlling mRNA stability, processing, and translation. Consequently, accurate identification of ac4C sites across the genome is critical for understanding gene expression regulation mechanisms. In this study, we have developed ac4C-AFL, a bioinformatics tool that precisely identifies ac4C sites from primary RNA sequences. In ac4C-AFL, we identified the optimal sequence length for model building and implemented an adaptive feature representation strategy that is capable of extracting the most representative features from RNA. To identify the most relevant features, we proposed a novel ensemble feature importance scoring strategy to rank features effectively. We then used this information to conduct the sequential forward search, which individually determine the optimal feature set from the 16 sequence-derived feature descriptors. Utilizing these optimal feature descriptors, we constructed 176 baseline models using 11 popular classifiers. The most efficient baseline models were identified using the two-step feature selection approach, whose predicted scores were integrated and trained with the appropriate classifier to develop the final prediction model. Our rigorous cross-validations and independent tests demonstrate that ac4C-AFL surpasses contemporary tools in predicting ac4C sites. Moreover, we have developed a publicly accessible web server at https://balalab-skku.org/ac4C-AFL/.
@article{pham2024ac4c, title = {ac4C-AFL: A high-precision identification of human mRNA N4-acetylcytidine sites based on adaptive feature representation learning}, author = {Pham, Nhat Truong and Terrance, Annie Terrina and Jeon, Young-Jun and Rakkiyappan, Rajan and Manavalan, Balachandran}, journal = {Molecular Therapy-Nucleic Acids}, volume = {35}, number = {2}, pages = {102192}, year = {2024}, publisher = {Elsevier}, doi = {10.1016/j.omtn.2024.102192}, } - Innovative Multi-Modal Control for Surveillance Spider Robot: An Integration of Voice and Hand Gesture RecognitionDang Khoa Phan , Phuong-Nam Tran , Nhat Truong Pham , Tra Huong Thi Le , and Duc Ngoc Minh Dang
The spider robot is designed to take on challenging tasks in hazardous conditions. It can move across challenging terrain like walls and rough surfaces, and effectively find lost objects. In this paper, an innovative multi-modal control approach was developed for the Surveillance Spider Robot (SSR) application, integrating voice recognition and hand gesture recognition as control commands. SSR, a six-legged robot, was designed using a Raspberry Pi 4B embedded device, Arduino Uno kit, RC Servo motors (MG996R), 18650 batteries, mini USB microphone (MI-350), Pi camera V1 (OV5647) and PWM generator (PCA9685). The robot can be controlled through voice or hand gesture recognition captured via camera and microphone. SSR is capable of performing ten specific tasks based on these control commands, including forward movement, backward movement, left turns, right turns, complete turns, movements with higher or lower centers of gravity, slow movement, body-hopping, and stopping. The performance evaluation of voice and hand gesture recognition suggested that SSR can be used in real-world applications with an accuracy that exceeds 90% for the ten specific tasks.
@inproceedings{phan2024innovative, title = {Innovative Multi-Modal Control for Surveillance Spider Robot: An Integration of Voice and Hand Gesture Recognition}, author = {Phan, Dang Khoa and Tran, Phuong-Nam and Pham, Nhat Truong and Le, Tra Huong Thi and Dang, Duc Ngoc Minh}, booktitle = {Proceedings of the 2024 9th International Conference on Intelligent Information Technology}, pages = {141--148}, year = {2024}, doi = {10.1145/3654522.3654544}, } - Deep Learning-Based Automated Cashier System for BakeriesNam Van Hai Phan , Tha Thanh Le , Tuan Phu Phan , Thu Thuy Le , Phuong-Nam Tran , Nhat Truong Pham , and Duc Ngoc Minh Dang
The application of image recognition in the bakery business has paved the way for automatic payment systems, a significant advancement in the field of computer vision. This article delves into an exploration of advanced image recognition models to meticulously assess their effectiveness, speed, and suitability for seamless integration into specialized automatic payment systems tailored for bakeries. Specifically, YOLOX, YOLOv8, Faster R-CNN, and RetinaNet, each with different versions and backbones, are considered for evaluation based on their speed and performance. Notably, this study introduces a streamlined process for rapidly creating custom datasets for object detection research and evaluates models across these datasets. The insights and analyses derived from this study provide valuable perspectives for optimizing processes and enhancing the overall performance of automatic payment systems within bakeries.
@inproceedings{phan2024deep, title = {Deep Learning-Based Automated Cashier System for Bakeries}, author = {Phan, Nam Van Hai and Le, Tha Thanh and Phan, Tuan Phu and Le, Thu Thuy and Tran, Phuong-Nam and Pham, Nhat Truong and Dang, Duc Ngoc Minh}, booktitle = {Proceedings of the 2024 9th International Conference on Intelligent Information Technology}, pages = {94--100}, year = {2024}, doi = {10.1145/3654522.3654538}, } - H2Opred: a robust and efficient hybrid deep learning model for predicting 2’-O-methylation sites in human RNA
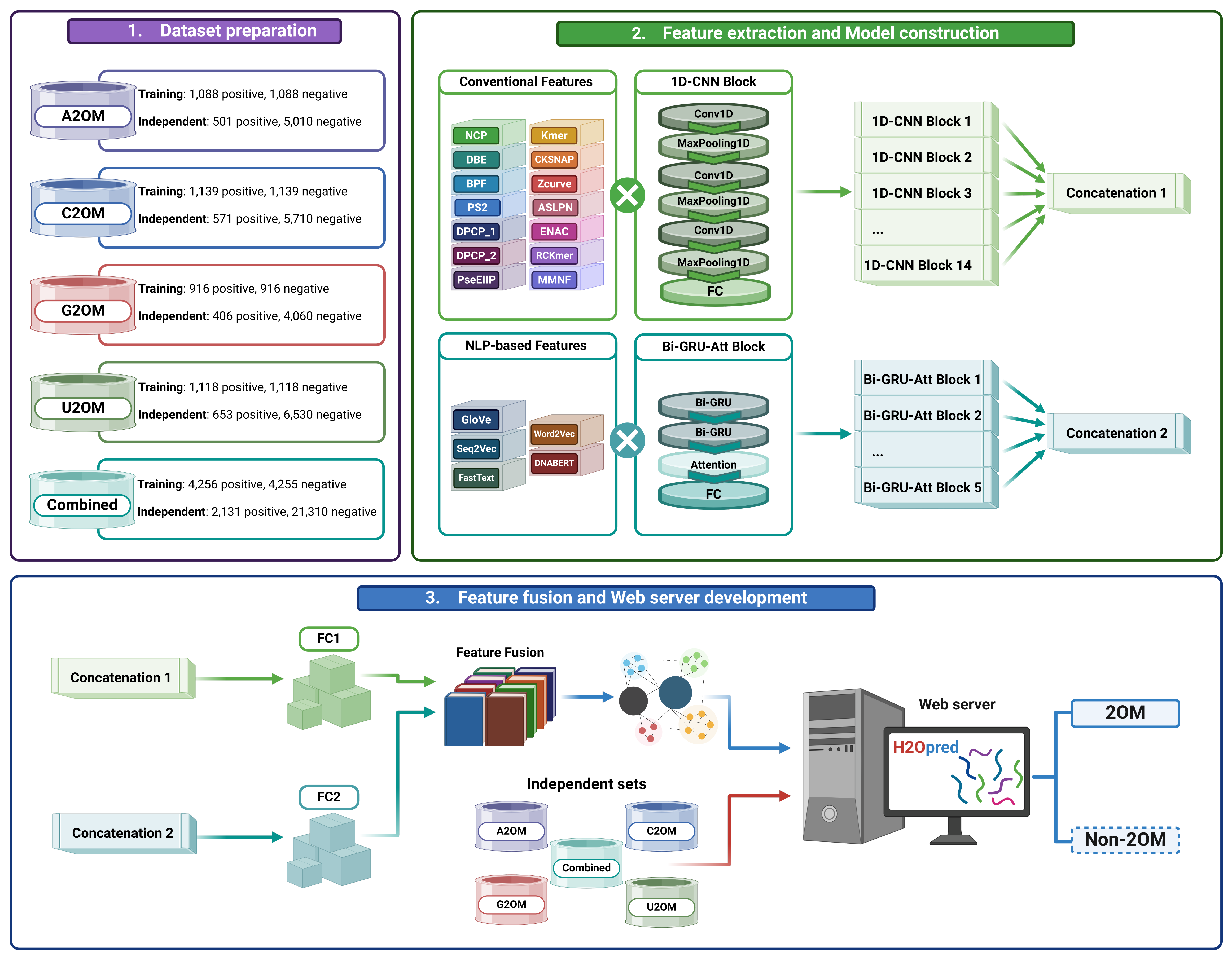
2’-O-methylation (2OM) is the most common post-transcriptional modification of RNA. It plays a crucial role in RNA splicing, RNA stability and innate immunity. Despite advances in high-throughput detection, the chemical stability of 2OM makes it difficult to detect and map in messenger RNA. Therefore, bioinformatics tools have been developed using machine learning (ML) algorithms to identify 2OM sites. These tools have made significant progress, but their performances remain unsatisfactory and need further improvement. In this study, we introduced H2Opred, a novel hybrid deep learning (HDL) model for accurately identifying 2OM sites in human RNA. Notably, this is the first application of HDL in developing four nucleotide-specific models [adenine (A2OM), cytosine (C2OM), guanine (G2OM) and uracil (U2OM)] as well as a generic model (N2OM). H2Opred incorporated both stacked 1D convolutional neural network (1D-CNN) blocks and stacked attention-based bidirectional gated recurrent unit (Bi-GRU-Att) blocks. 1D-CNN blocks learned effective feature representations from 14 conventional descriptors, while Bi-GRU-Att blocks learned feature representations from five natural language processing-based embeddings extracted from RNA sequences. H2Opred integrated these feature representations to make the final prediction. Rigorous cross-validation analysis demonstrated that H2Opred consistently outperforms conventional ML-based single-feature models on five different datasets. Moreover, the generic model of H2Opred demonstrated a remarkable performance on both training and testing datasets, significantly outperforming the existing predictor and other four nucleotide-specific H2Opred models. To enhance accessibility and usability, we have deployed a user-friendly web server for H2Opred, accessible at https://balalab-skku.org/H2Opred/. This platform will serve as an invaluable tool for accurately predicting 2OM sites within human RNA, thereby facilitating broader applications in relevant research endeavors.
@article{pham2024h2opred, title = {H2Opred: a robust and efficient hybrid deep learning model for predicting 2'-O-methylation sites in human RNA}, author = {Pham, Nhat Truong and Rakkiyappan, Rajan and Park, Jongsun and Malik, Adeel and Manavalan, Balachandran}, journal = {Briefings in Bioinformatics}, volume = {25}, number = {1}, pages = {bbad476}, year = {2024}, publisher = {Oxford University Press}, doi = {10.1093/bib/bbad476}, } - Advancing the accuracy of SARS-CoV-2 phosphorylation site detection via meta-learning approachNhat Truong Pham† , Le Thi Phan† , Jimin Seo , Yeonwoo Kim , Minkyung Song , Sukchan Lee , Young-Jun Jeon , and Balachandran Manavalan
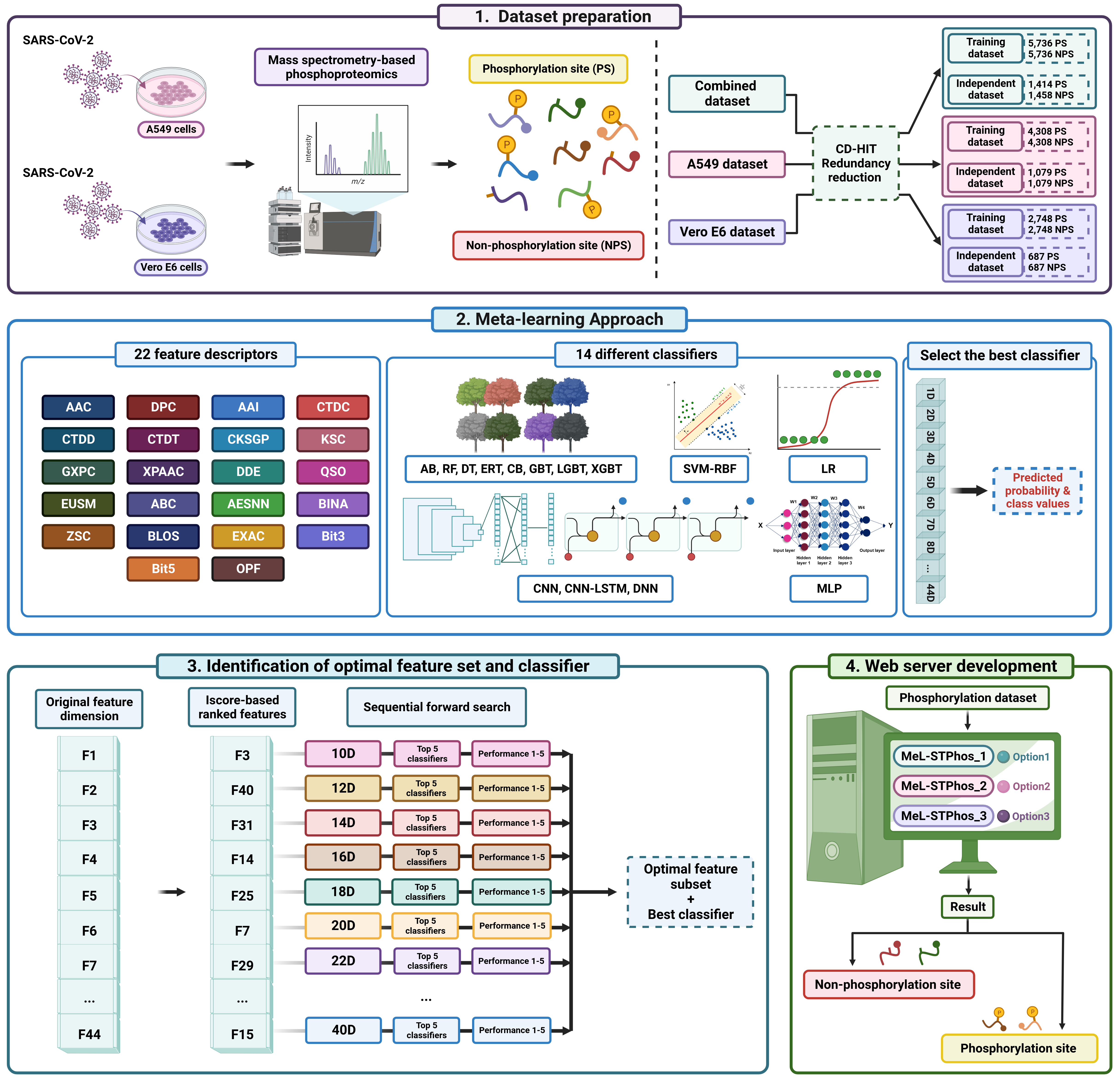
The worldwide appearance of severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) has generated significant concern and posed a considerable challenge to global health. Phosphorylation is a common post-translational modification that affects many vital cellular functions and is closely associated with SARS-CoV-2 infection. Precise identification of phosphorylation sites could provide more in-depth insight into the processes underlying SARS-CoV-2 infection and help alleviate the continuing coronavirus disease 2019 (COVID-19) crisis. Currently, available computational tools for predicting these sites lack accuracy and effectiveness. In this study, we designed an innovative meta-learning model, Meta-Learning for Serine/Threonine Phosphorylation (MeL-STPhos), to precisely identify protein phosphorylation sites. We initially performed a comprehensive assessment of 29 unique sequence-derived features, establishing prediction models for each using 14 renowned machine learning methods, ranging from traditional classifiers to advanced deep learning algorithms. We then selected the most effective model for each feature by integrating the predicted values. Rigorous feature selection strategies were employed to identify the optimal base models and classifier(s) for each cell-specific dataset. To the best of our knowledge, this is the first study to report two cell-specific models and a generic model for phosphorylation site prediction by utilizing an extensive range of sequence-derived features and machine learning algorithms. Extensive cross-validation and independent testing revealed that MeL-STPhos surpasses existing state-of-the-art tools for phosphorylation site prediction. We also developed a publicly accessible platform at https://balalab-skku.org/MeL-STPhos/. We believe that MeL-STPhos will serve as a valuable tool for accelerating the discovery of serine/threonine phosphorylation sites and elucidating their role in post-translational regulation.
@article{pham2024advancing, title = {Advancing the accuracy of SARS-CoV-2 phosphorylation site detection via meta-learning approach}, author = {Pham, Nhat Truong and Phan, Le Thi and Seo, Jimin and Kim, Yeonwoo and Song, Minkyung and Lee, Sukchan and Jeon, Young-Jun and Manavalan, Balachandran}, journal = {Briefings in Bioinformatics}, volume = {25}, number = {1}, pages = {bbad433}, year = {2024}, publisher = {Oxford University Press}, doi = {10.1093/bib/bbad433}, }



2023
- Comparative analysis of multi-loss functions for enhanced multi-modal speech emotion recognitionPhuong-Nam Tran , Thuy-Duong Thi Vu , Nhat Truong Pham , Hanh Dang-Ngoc , and Duc Ngoc Minh DangIn 2023 14th International Conference on Information and Communication Technology Convergence (ICTC), 2023
In recent years, multi-modal analysis has gained significant prominence across domains such as audio/speech processing, natural language processing, and affective computing, with a particular focus on speech emotion recognition (SER). The integration of data from diverse sources, encompassing text, audio, and images, in conjunction with classifier algorithms has led to the realization of enhanced performance in SER tasks. Traditionally, the cross-entropy loss function has been employed for the classification problem. However, it is challenging to discriminate the feature representations among classes for multi-modal classification tasks. In this study, we focus on the impact of the loss functions on multi-modal SER rather than designing the model architecture. Mainly, we evaluate the performance of multi-modal SER with different loss functions, such as cross-entropy loss, center loss, contrastive-center loss, and their combinations. Based on extensive comparative analysis, it is proven that the combination of cross-entropy loss and contrastive-center loss achieves the best performance for multi-modal SER. This combination reaches the highest accuracy of 80.27% and the highest balanced accuracy of 81.44% on the IEMOCAP dataset.
@inproceedings{tran2023comparative, title = {Comparative analysis of multi-loss functions for enhanced multi-modal speech emotion recognition}, author = {Tran, Phuong-Nam and Vu, Thuy-Duong Thi and Pham, Nhat Truong and Dang-Ngoc, Hanh and Dang, Duc Ngoc Minh}, booktitle = {2023 14th International Conference on Information and Communication Technology Convergence ICTC}, pages = {425--429}, year = {2023}, organization = {IEEE}, doi = {10.1109/ICTC58733.2023.10392928}, } - SER-Fuse: An Emotion Recognition Application Utilizing Multi-Modal, Multi-Lingual, and Multi-Feature FusionNhat Truong Pham* , Le Thi Phan , Duc Ngoc Minh Dang , and Balachandran ManavalanIn Proceedings of the 12th International Symposium on Information and Communication Technology, 2023
Speech emotion recognition (SER) is a crucial aspect of affective computing and human-computer interaction, yet effectively identifying emotions in different speakers and languages remains challenging. This paper introduces SER-Fuse, a multi-modal SER application that is designed to address the complexities of multiple speakers and languages. Our approach leverages diverse audio/speech embeddings and text embeddings to extract optimal features for multi-modal SER. We subsequently employ multi-feature fusion to integrate embedding features across modalities and languages. Experimental results archived on the English-Chinese emotional speech (ECES) dataset reveal that SER-Fuse attains competitive performance in the multi-lingual approach compared to the single-lingual approaches. Furthermore, we provide the implementation of SER-Fuse for download at https://github.com/nhattruongpham/SER-Fuse/ to support reproducibility and local deployment.
@inproceedings{pham2023serfuse, title = {SER-Fuse: An Emotion Recognition Application Utilizing Multi-Modal, Multi-Lingual, and Multi-Feature Fusion}, author = {Pham, Nhat Truong and Phan, Le Thi and Dang, Duc Ngoc Minh and Manavalan, Balachandran}, booktitle = {Proceedings of the 12th International Symposium on Information and Communication Technology}, pages = {870--877}, year = {2023}, doi = {10.1145/3628797.3628887}, } - Multi-modal Speech Emotion Recognition: Improving Accuracy Through Fusion of VGGish and BERT Features with Multi-head AttentionPhuong-Nam Tran , Thuy-Duong Thi Vu , Duc Ngoc Minh Dang , Nhat Truong Pham , and Anh-Khoa Tran
Recent research has shown that multi-modal learning is a successful method for enhancing classification performance by mixing several forms of input, notably in speech-emotion recognition (SER) tasks. However, the difference between the modalities may affect SER performance. To overcome this problem, a novel approach for multi-modal SER called 3M-SER is proposed in this paper. The 3M-SER leverages multi-head attention to fuse information from multiple feature embeddings, including audio and text features. The 3M-SER approach is based on the SERVER approach but includes an additional fusion module that improves the integration of text and audio features, leading to improved classification performance. To further enhance the correlation between the modalities, a LayerNorm is applied to audio features prior to fusion. Our approach achieved an unweighted accuracy (UA) and weighted accuracy (WA) of 79.96% and 80.66%, respectively, on the IEMOCAP benchmark dataset. This indicates that the proposed approach is better than SERVER and recent methods with similar approaches. In addition, it highlights the effectiveness of incorporating an extra fusion module in multi-modal learning.
@inproceedings{tran2023multi, title = {Multi-modal Speech Emotion Recognition: Improving Accuracy Through Fusion of VGGish and BERT Features with Multi-head Attention}, author = {Tran, Phuong-Nam and Vu, Thuy-Duong Thi and Dang, Duc Ngoc Minh and Pham, Nhat Truong and Tran, Anh-Khoa}, booktitle = {International Conference on Industrial Networks and Intelligent Systems}, pages = {148--158}, year = {2023}, organization = {Springer}, doi = {10.1007/978-3-031-47359-3_11}, } - ADP-Fuse: A novel dual layer machine learning predictor to identify antidiabetic peptides and diabetes types using multiview informationShaherin Basith , Nhat Truong Pham , Minkyung Song , Gwang Lee , and Balachandran Manavalan
Diabetes mellitus has become a major public health concern associated with high mortality and reduced life expectancy and can cause blindness, heart attacks, kidney failure, lower limb amputations, and strokes. A new generation of antidiabetic peptides (ADPs) that act on β-cells or T-cells to regulate insulin production is being developed to alleviate the effects of diabetes. However, the lack of effective peptide-mining tools has hampered the discovery of these promising drugs. Hence, novel computational tools need to be developed urgently. In this study, we present ADP-Fuse, a novel two-layer prediction framework capable of accurately identifying ADPs or non-ADPs and categorizing them into type 1 and type 2 ADPs. First, we comprehensively evaluated 22 peptide sequence-derived features coupled with eight notable machine learning algorithms. Subsequently, the most suitable feature descriptors and classifiers for both layers were identified. The output of these single-feature models, embedded with multiview information, was trained with an appropriate classifier to provide the final prediction. Comprehensive cross-validation and independent tests substantiate that ADP-Fuse surpasses single-feature models and the feature fusion approach for the prediction of ADPs and their types. In addition, the SHapley Additive exPlanation method was used to elucidate the contributions of individual features to the prediction of ADPs and their types. Finally, a user-friendly web server for ADP-Fuse was developed and made publicly accessible (https://balalab-skku.org/ADP-Fuse/), enabling the swift screening and identification of novel ADPs and their types. This framework is expected to contribute significantly to antidiabetic peptide identification.
@article{basith2023adp, title = {ADP-Fuse: A novel dual layer machine learning predictor to identify antidiabetic peptides and diabetes types using multiview information}, author = {Basith, Shaherin and Pham, Nhat Truong and Song, Minkyung and Lee, Gwang and Manavalan, Balachandran}, journal = {Computers in Biology and Medicine}, volume = {165}, pages = {107386}, year = {2023}, publisher = {Elsevier}, doi = {10.1016/j.compbiomed.2023.107386}, } - SERVER: Multi-modal Speech Emotion Recognition using TransformeR-based and Vision-based EmbeddingsNhat Truong Pham , Duc Ngoc Minh Dang , Bich Hong Ngoc Pham , and Sy Dzung Nguyen
This paper proposes a multi-modal approach for speech emotion recognition (SER) using both text and audio inputs. The audio embedding is extracted by using a vision-based architecture, namely VGGish, while the text embedding is extracted by using a transformer-based architecture, namely BERT. Then, these embeddings are fused using concatenation to recognize emotional states. To evaluate the effectiveness of the proposed method, the benchmark dataset, namely IEMOCAP, is employed in this study. Experimental results indicate that the proposed method is very competitive and better than most of the latest and state-of-the-art methods using multi-modal analysis for SER. The proposed method achieves 63.00% unweighted accuracy (UA) and 63.10% weighted accuracy (WA) on the IEMOCAP dataset. In the future, an extension of multi-task learning and multi-lingual approaches will be investigated to improve the performance and robustness of multi-modal SER. For reproducibility purposes, our code is publicly available.
@inproceedings{pham2023server, title = {SERVER: Multi-modal Speech Emotion Recognition using TransformeR-based and Vision-based Embeddings}, author = {Pham, Nhat Truong and Dang, Duc Ngoc Minh and Pham, Bich Hong Ngoc and Nguyen, Sy Dzung}, booktitle = {Proceedings of the 2023 8th International Conference on Intelligent Information Technology}, pages = {234--238}, year = {2023}, doi = {10.1145/3591569.3591610}, } - Uplink registration-based MAC protocol for IEEE 802.11ah networksDuc Ngoc Minh Dang , and Nhat Truong Pham
IEEE 802.11ah (Wi-Fi HaLow) operates in license-exempt ISM bands below 1 GHz and provides longer-range connectivity. The main advantage of the IEEE 802.11ah is it provides long range connection with low power consumption. RAW (Restricted Access Window) in IEEE 802.11ah helps to reduce the collision probability and enhance the network throughput when many stations contend the channel. Since stations are assigned to uplink RAW slots based on their Association Identifications (AID), the number of stations that have uplink data packets in each RAW slot is a big difference. It results in low fairness among stations. The paper proposes an uplink registration-based MAC protocol for IEEE 802.11ah networks (UR-MAC). In UR-MAC protocol, stations with uplink data will register with the AP by attaching the uplink registration to the data packet during downlink communications. The AP will allocate RAW slots based on the uplink registered station list. The UR-MAC protocol tries to use up the resources of the RAW slots as well as balance the number of stations with uplink data among the RAW slots. Through the evaluation and comparison analysis, the UR-MAC protocol significantly improves the fairness index compared to the IEEE 802.11ah protocol while still ensuring the probability of successful transmission, the average number of successfully transmitted packets, and power efficiency compared to the IEEE 802.11ah protocol.
@inproceedings{dang2023uplink, title = {Uplink registration-based MAC protocol for IEEE 802.11ah networks}, author = {Dang, Duc Ngoc Minh and Pham, Nhat Truong}, booktitle = {Proceedings of the 2023 8th International Conference on Intelligent Information Technology}, pages = {33--37}, year = {2023}, doi = {10.1145/3591569.3591575}, } - DrugormerDTI: Drug Graphormer for drug–target interaction predictionJiayue Hu , Wang Yu , Chao Pang , Junru Jin , Nhat Truong Pham , Balachandran Manavalan , and Leyi Wei
Drug-target interactions (DTI) prediction is a crucial task in drug discovery. Existing computational methods accelerate the drug discovery in this respect. However, most of them suffer from low feature representation ability, significantly affecting the predictive performance. To address the problem, we propose a novel neural network architecture named DrugormerDTI, which uses Graph Transformer to learn both sequential and topological information through the input molecule graph and Resudual2vec to learn the underlying relation between residues from proteins. By conducting ablation experiments, we verify the importance of each part of the DrugormerDTI. We also demonstrate the good feature extraction and expression capabilities of our model via comparing the mapping results of the attention layer and molecular docking results. Experimental results show that our proposed model performs better than baseline methods on four benchmarks. We demonstrate that the introduction of Graph Transformer and the design of residue are appropriate for drug-target prediction.
@article{hu2023drugormerdti, title = {DrugormerDTI: Drug Graphormer for drug--target interaction prediction}, author = {Hu, Jiayue and Yu, Wang and Pang, Chao and Jin, Junru and Pham, Nhat Truong and Manavalan, Balachandran and Wei, Leyi}, journal = {Computers in Biology and Medicine}, volume = {161}, pages = {106946}, year = {2023}, publisher = {Elsevier}, doi = {10.1016/j.compbiomed.2023.106946}, } - AAD-Net: Advanced end-to-end signal processing system for human emotion detection & recognition using attention-based deep echo state networkMustaqeem Khan , Abdulmotaleb El Saddik , Fahd Saleh Alotaibi , and Nhat Truong PhamKnowledge-Based Systems, 2023
Speech signals are the most convenient way of communication between human beings and the eventual method of Human-Computer Interaction (HCI) to exchange emotions and information. Recognizing emotions from speech signals is a challenging task due to the sparse nature of emotional data and features. In this article, we proposed a Deep Echo-State-Network (DeepESN) system for emotion recognition with a dilated convolution neural network and multi-headed attention mechanism. To reduce the model complexity, we incorporate a DeepESN that combines reservoir computing for higher-dimensional mapping. We also used fine-tuned Sparse Random Projection (SRP) to reduce dimensionality and adopted an early fusion strategy to fuse the extracted cues and passed the joint feature vector via a classification layer to recognize emotions. Our proposed model is evaluated on two public speech corpora, EMO-DB and RAVDESS, and tested for subject/speaker-dependent/independent performance. The results show that our proposed system achieves a high recognition rate, 91.14, 85.57 for EMO-DB, and 82.01, 77.02 for RAVDESS, using speaker-dependent and independent experiments, respectively. Our proposed system outperforms the State-of-The-Art (SOTA) while requiring less computational time.
@article{mustaqeem2023aad, title = {AAD-Net: Advanced end-to-end signal processing system for human emotion detection \& recognition using attention-based deep echo state network}, author = {Khan, Mustaqeem and El Saddik, Abdulmotaleb and Alotaibi, Fahd Saleh and Pham, Nhat Truong}, journal = {Knowledge-Based Systems}, volume = {270}, pages = {110525}, year = {2023}, publisher = {Elsevier}, doi = {10.1016/j.knosys.2023.110525}, } - Towards an efficient machine learning model for financial time series forecastingArun Kumar , Tanya Chauhan , Srinivasan Natesan , Nhat Truong Pham , Ngoc Duy Nguyen , and Chee Peng LimSoft Computing, 2023
Financial time series forecasting is a challenging problem owing to the high degree of randomness and absence of residuals in time series data. Existing machine learning solutions normally do not perform well on such data. In this study, we propose an efficient machine learning model for financial time series forecasting through carefully designed feature extraction, elimination, and selection strategies. We leverage a binary particle swarm optimization algorithm to select the appropriate features and propose new evaluation metrics, i.e. mean weighted square error and mean weighted square ratio, for better performance assessment in handling financial time series data. Both indicators ascertain that our proposed model is effective, which outperforms several existing methods in benchmark studies.
@article{kumar2023towards, title = {Towards an efficient machine learning model for financial time series forecasting}, author = {Kumar, Arun and Chauhan, Tanya and Natesan, Srinivasan and Pham, Nhat Truong and Nguyen, Ngoc Duy and Lim, Chee Peng}, journal = {Soft Computing}, volumev = {27}, pages = {11329--11339}, year = {2023}, publisher = {Springer}, doi = {10.1007/s00500-023-08676-x}, } - Hybrid data augmentation and deep attention-based dilated convolutional-recurrent neural networks for speech emotion recognitionNhat Truong Pham , Duc Ngoc Minh Dang , Ngoc Duy Nguyen , Thanh Thi Nguyen , Hai Nguyen , Balachandran Manavalan , Chee Peng Lim , and Sy Dzung Nguyen
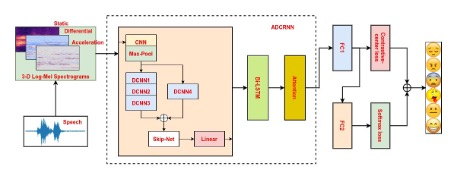
Recently, speech emotion recognition (SER) has become an active research area in speech processing, particularly with the advent of deep learning (DL). Numerous DL-based methods have been proposed for SER. However, most of the existing DL-based models are complex and require a large amounts of data to achieve a good performance. In this study, a new framework of deep attention-based dilated convolutional-recurrent neural networks coupled with a hybrid data augmentation method was proposed for addressing SER tasks. The hybrid data augmentation method constitutes an upsampling technique for generating more speech data samples based on the traditional and generative adversarial network approaches. By leveraging both convolutional and recurrent neural networks in a dilated form along with an attention mechanism, the proposed DL framework can extract high-level representations from three-dimensional log Mel spectrogram features. Dilated convolutional neural networks acquire larger receptive fields, whereas dilated recurrent neural networks overcome complex dependencies as well as the vanishing and exploding gradient issues. Furthermore, the loss functions are reconfigured by combining the SoftMax loss and the center-based losses to classify various emotional states. The proposed framework was implemented using the Python programming language and the TensorFlow deep learning library. To validate the proposed framework, the EmoDB and ERC benchmark datasets, which are imbalanced and/or small datasets, were employed. The experimental results indicate that the proposed framework outperforms other related state-of-the-art methods, yielding the highest unweighted recall rates of 88.03 ± 1.39 (%) and 66.56 ± 0.67 (%) for the EmoDB and ERC datasets, respectively.
@article{pham2023hybrid, title = {Hybrid data augmentation and deep attention-based dilated convolutional-recurrent neural networks for speech emotion recognition}, author = {Pham, Nhat Truong and Dang, Duc Ngoc Minh and Nguyen, Ngoc Duy and Nguyen, Thanh Thi and Nguyen, Hai and Manavalan, Balachandran and Lim, Chee Peng and Nguyen, Sy Dzung}, journal = {Expert Systems with Applications}, pages = {120608}, year = {2023}, publisher = {Elsevier}, doi = {10.1016/j.eswa.2023.120608}, } - Pretoria: An effective computational approach for accurate and high-throughput identification of CD8+ t-cell epitopes of eukaryotic pathogensPhasit Charoenkwan , Nalini Schaduangrat , Nhat Truong Pham , Balachandran Manavalan , and Watshara Shoombuatong
T-cells recognize antigenic epitopes present on major histocompatibility complex (MHC) molecules, triggering an adaptive immune response in the host. T-cell epitope (TCE) identification is challenging because of the extensive number of undetermined proteins found in eukaryotic pathogens, as well as MHC polymorphisms. In addition, conventional experimental approaches for TCE identification are time-consuming and expensive. Thus, computational approaches that can accurately and rapidly identify CD8+ T-cell epitopes (TCEs) of eukaryotic pathogens based solely on sequence information may facilitate the discovery of novel CD8+ TCEs in a cost-effective manner. Here, Pretoria (Predictor of CD8+ TCEs of eukaryotic pathogens) is proposed as the first stack-based approach for accurate and large-scale identification of CD8+ TCEs of eukaryotic pathogens. In particular, Pretoria enabled the extraction and exploration of crucial information embedded in CD8+ TCEs by employing a comprehensive set of 12 well-known feature descriptors extracted from multiple groups, including physicochemical properties, composition-transition-distribution, pseudo-amino acid composition, and amino acid composition. These feature descriptors were then utilized to construct a pool of 144 different machine learning (ML)-based classifiers based on 12 popular ML algorithms. Finally, the feature selection method was used to effectively determine the important ML classifiers for the construction of our stacked model. The experimental results indicated that Pretoria is an accurate and effective computational approach for CD8+ TCE prediction; it was superior to several conventional ML classifiers and the existing method in terms of the independent test, with an accuracy of 0.866, MCC of 0.732, and AUC of 0.921. Additionally, to maximize user convenience for high-throughput identification of CD8+ TCEs of eukaryotic pathogens, a user-friendly web server of Pretoria (http://pmlabstack.pythonanywhere.com/Pretoria) was developed and made freely available.
@article{charoenkwan2023pretoria, title = {Pretoria: An effective computational approach for accurate and high-throughput identification of CD8+ t-cell epitopes of eukaryotic pathogens}, author = {Charoenkwan, Phasit and Schaduangrat, Nalini and Pham, Nhat Truong and Manavalan, Balachandran and Shoombuatong, Watshara}, journal = {International Journal of Biological Macromolecules}, volume = {238}, pages = {124228}, year = {2023}, publisher = {Elsevier}, doi = {10.1016/j.ijbiomac.2023.124228}, } - Speech emotion recognition using overlapping sliding window and Shapley additive explainable deep neural networkNhat Truong Pham , Sy Dzung Nguyen , Vu Song Thuy Nguyen , Bich Ngoc Hong Pham , and Duc Ngoc Minh Dang
Speech emotion recognition (SER) has several applications, such as e-learning, human-computer interaction, customer service, and healthcare systems. Although researchers have investigated lots of techniques to improve the accuracy of SER, it has been challenging with feature extraction, classifier schemes, and computational costs. To address the aforementioned problems, we propose a new set of 1D features extracted by using an overlapping sliding window (OSW) technique for SER in this study. In addition, a deep neural network-based classifier scheme called the deep Pattern Recognition Network (PRN) is designed to categorize emotional states from the new set of 1D features. We evaluate the proposed method on the Emo-DB and the AESSD datasets that contain several different emotional states. The experimental results show that the proposed method achieves an accuracy of 98.5% and 87.1% on the Emo-DB and AESSD datasets, respectively. It is also more comparable with accuracy to and better than the state-of-the-art and current approaches that use 1D features on the same datasets for SER. Furthermore, the SHAP (SHapley Additive exPlanations) analysis is employed for interpreting the prediction model to assist system developers in selecting the optimal features to integrate into the desired system.
@article{pham2023speech, title = {Speech emotion recognition using overlapping sliding window and Shapley additive explainable deep neural network}, author = {Pham, Nhat Truong and Nguyen, Sy Dzung and Nguyen, Vu Song Thuy and Pham, Bich Ngoc Hong and Dang, Duc Ngoc Minh}, journal = {Journal of Information and Telecommunication}, volumevo = {7}, number = {3}, pages = {317--335}, year = {2023}, publisher = {Taylor & Francis}, doi = {10.1080/24751839.2023.2187278}, } - Fruit-CoV: An efficient vision-based framework for speedy detection and diagnosis of SARS-CoV-2 infections through recorded cough soundsLong H. Nguyen† , Nhat Truong Pham†* , Van Huong Do , Liu Tai Nguyen , Thanh Tin Nguyen , Hai Nguyen , Ngoc Duy Nguyen , Thanh Thi Nguyen , Sy Dzung Nguyen , Asim Bhatti , and Chee Peng Lim
COVID-19 is an infectious disease caused by the severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2). This deadly virus has spread worldwide, leading to a global pandemic since March 2020. A recent variant of SARS-CoV-2 named Delta is intractably contagious and responsible for more than four million deaths globally. Therefore, developing an efficient self-testing service for SARS-CoV-2 at home is vital. In this study, a two-stage vision-based framework, namely Fruit-CoV, is introduced for detecting SARS-CoV-2 infections through recorded cough sounds. Specifically, audio signals are converted into Log-Mel spectrograms, and the EfficientNet-V2 network is used to extract their visual features in the first stage. In the second stage, 14 convolutional layers extracted from the large-scale Pretrained Audio Neural Networks for audio pattern recognition (PANNs) and the Wavegram-Log-Mel-CNN are employed to aggregate feature representations of the Log-Mel spectrograms and the waveform. Finally, the combined features are used to train a binary classifier. In this study, a dataset provided by the AICovidVN 115M Challenge is employed for evaluation. It includes 7,371 recorded cough sounds collected throughout Vietnam, India, and Switzerland. Experimental results indicate that the proposed model achieves an Area Under the Receiver Operating Characteristic Curve (AUC) score of 92.8% and ranks first on the final leaderboard of the AICovidVN 115M Challenge. Our code is publicly available.
@article{nguyen2023fruit, title = {Fruit-CoV: An efficient vision-based framework for speedy detection and diagnosis of SARS-CoV-2 infections through recorded cough sounds}, author = {Nguyen, Long H. and Pham, Nhat Truong and Do, Van Huong and Nguyen, Liu Tai and Nguyen, Thanh Tin and Nguyen, Hai and Nguyen, Ngoc Duy and Nguyen, Thanh Thi and Nguyen, Sy Dzung and Bhatti, Asim and Lim, Chee Peng}, journal = {Expert Systems with Applications}, volume = {213}, pages = {119212}, year = {2023}, publisher = {Elsevier}, doi = {10.1016/j.eswa.2022.119212}, } - Towards designing a generic and comprehensive deep reinforcement learning frameworkNgoc Duy Nguyen , Thanh Thi Nguyen , Nhat Truong Pham , Hai Nguyen , Dang Tu Nguyen , Thanh Dang Nguyen , Chee Peng Lim , Michael Johnstone , Asim Bhatti , Douglas Creighton , and Saeid NahavandiApplied Intelligence, 2023
Reinforcement learning (RL) has emerged as an effective approach for building an intelligent system, which involves multiple self-operated agents to collectively accomplish a designated task. More importantly, there has been a renewed focus on RL since the introduction of deep learning that essentially makes RL feasible to operate in high-dimensional environments. However, there are many diversified research directions in the current literature, such as multi-agent and multi-objective learning, and human-machine interactions. Therefore, in this paper, we propose a comprehensive software architecture that not only plays a vital role in designing a connect-the-dots deep RL architecture but also provides a guideline to develop a realistic RL application in a short time span. By inheriting the proposed architecture, software managers can foresee any challenges when designing a deep RL-based system. As a result, they can expedite the design process and actively control every stage of software development, which is especially critical in agile development environments. For this reason, we design a deep RL-based framework that strictly ensures flexibility, robustness, and scalability. To enforce generalization, the proposed architecture also does not depend on a specific RL algorithm, a network configuration, the number of agents, or the type of agents.
@article{nguyen2023towards, title = {Towards designing a generic and comprehensive deep reinforcement learning framework}, author = {Nguyen, Ngoc Duy and Nguyen, Thanh Thi and Pham, Nhat Truong and Nguyen, Hai and Nguyen, Dang Tu and Nguyen, Thanh Dang and Lim, Chee Peng and Johnstone, Michael and Bhatti, Asim and Creighton, Douglas and Nahavandi, Saeid}, journal = {Applied Intelligence}, volume = {53}, number = {3}, pages = {2967--2988}, year = {2023}, publisher = {Springer}, doi = {10.1007/s10489-022-03550-z}, }

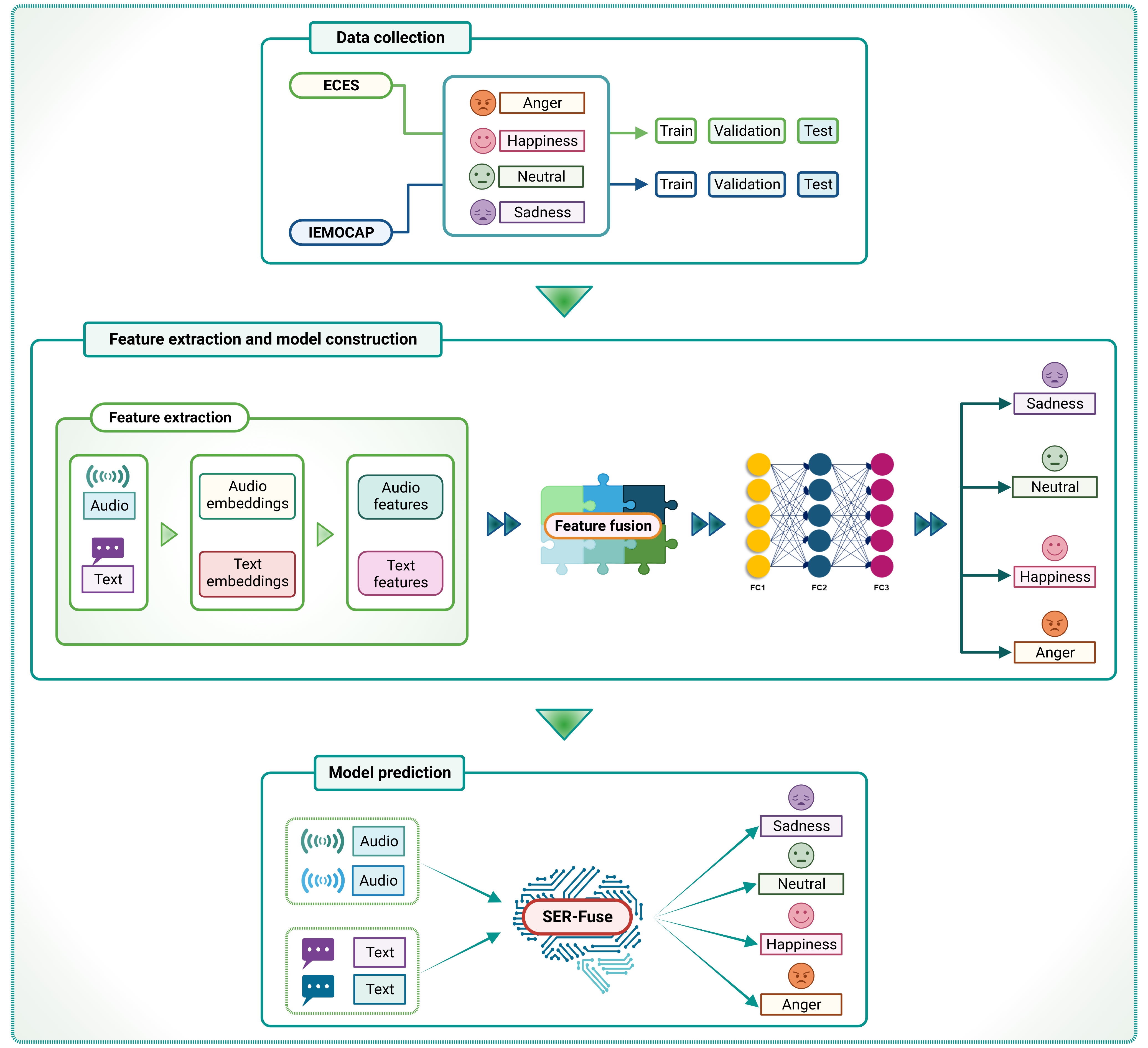

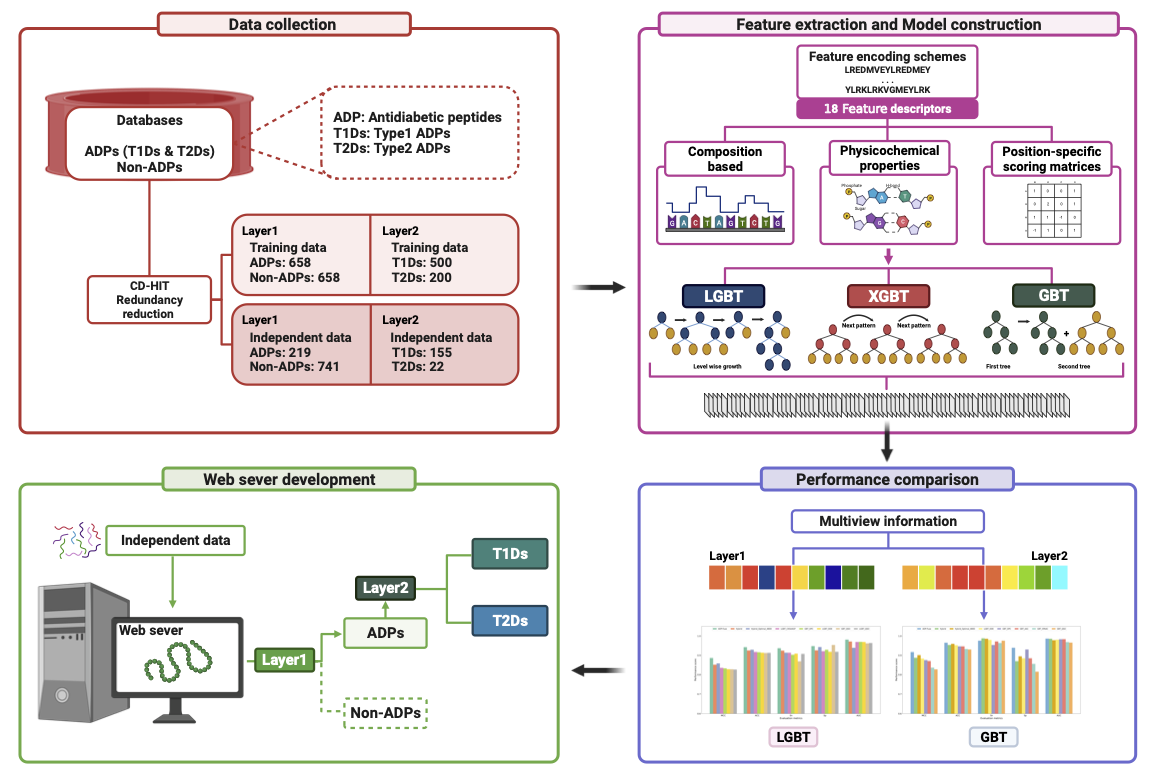

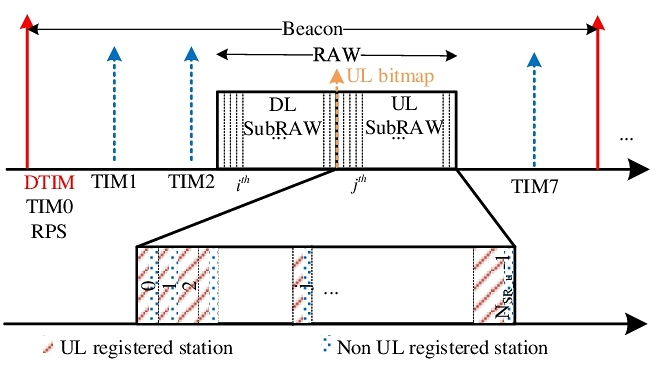
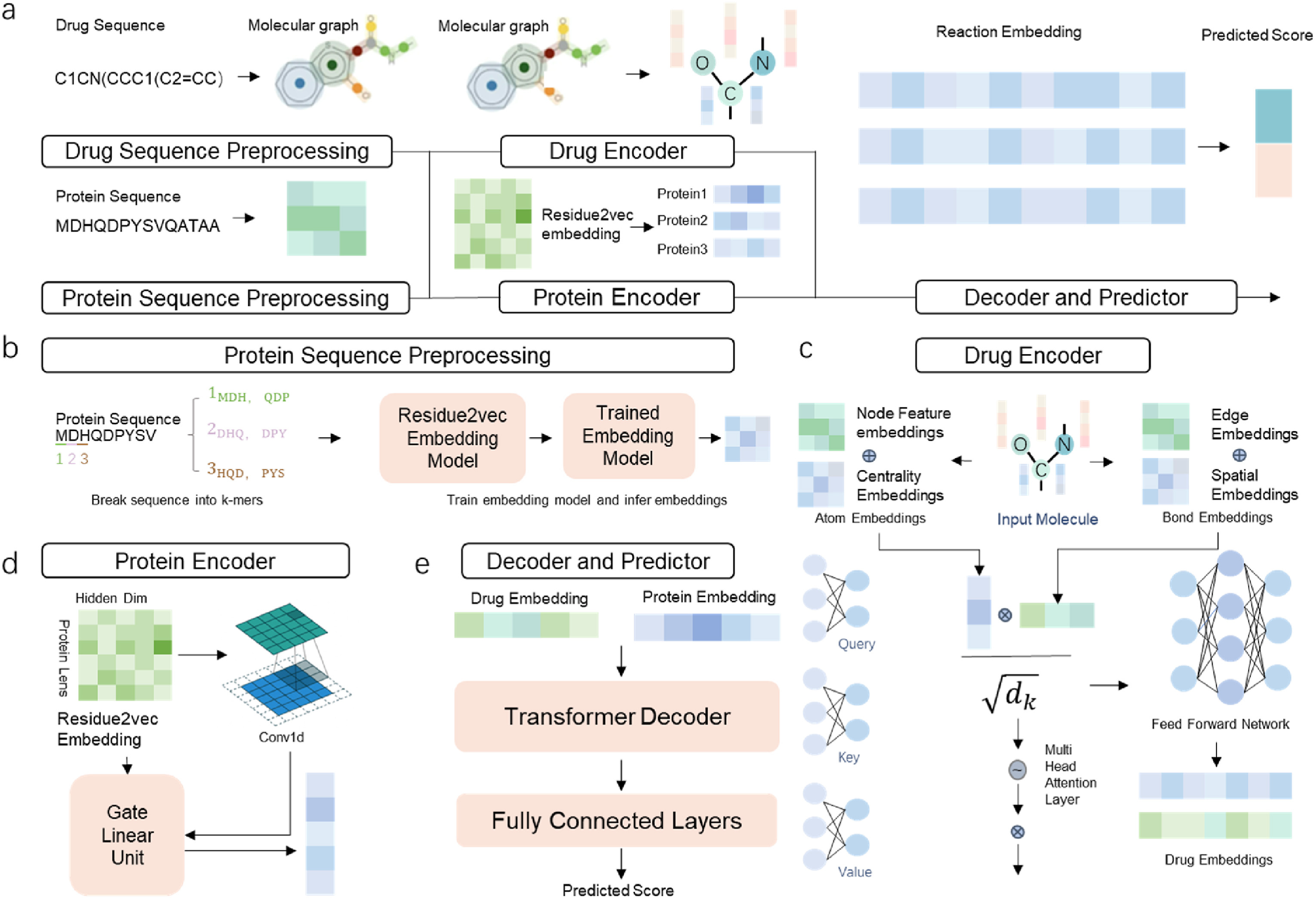
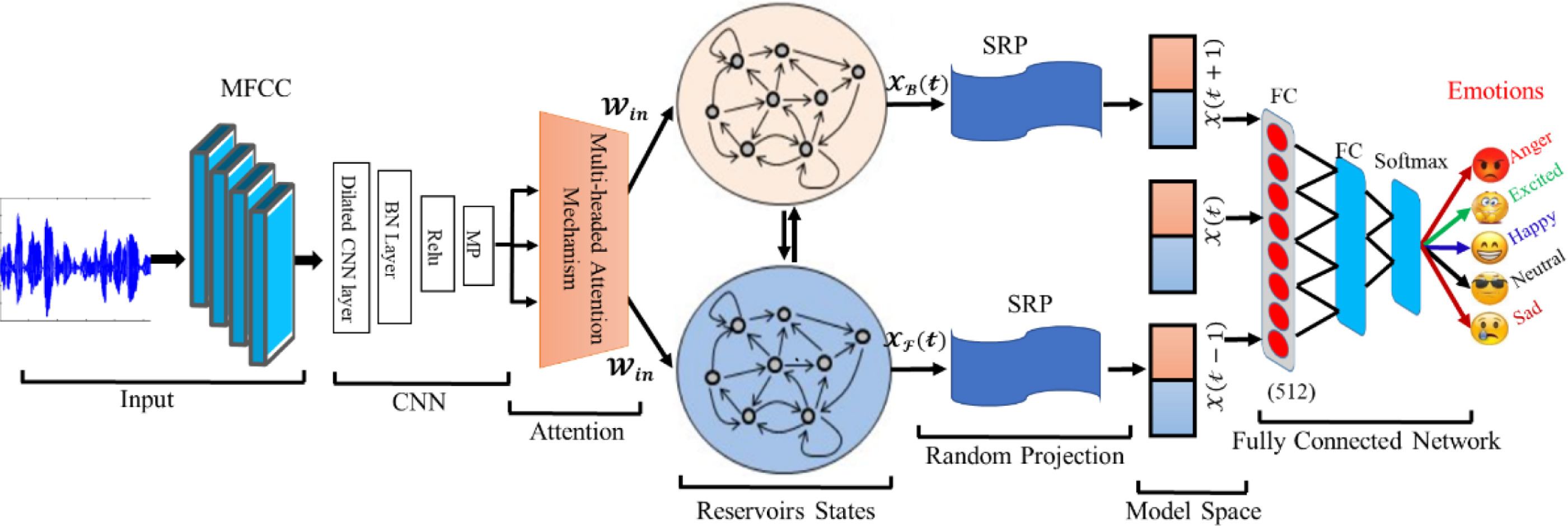
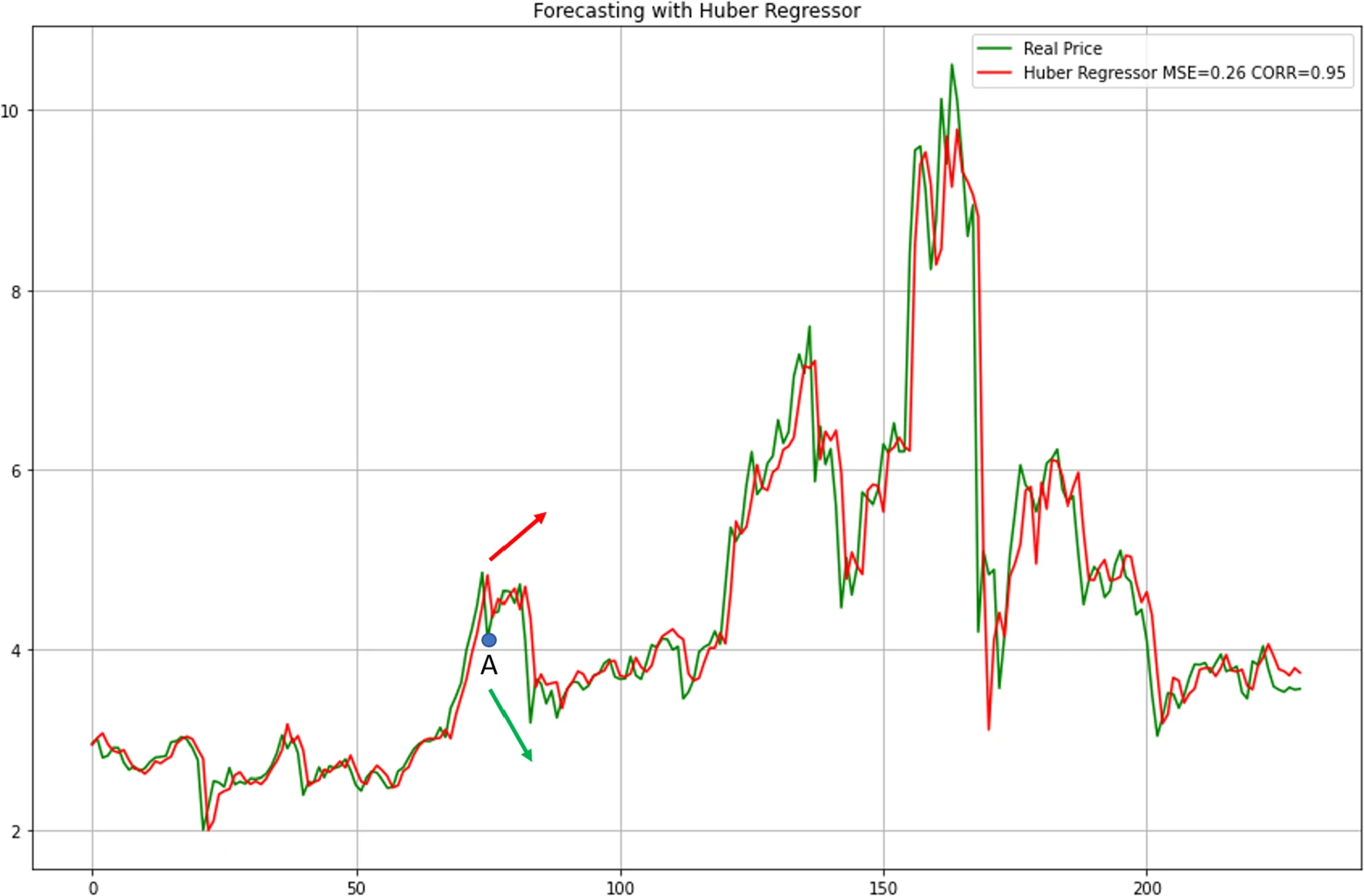
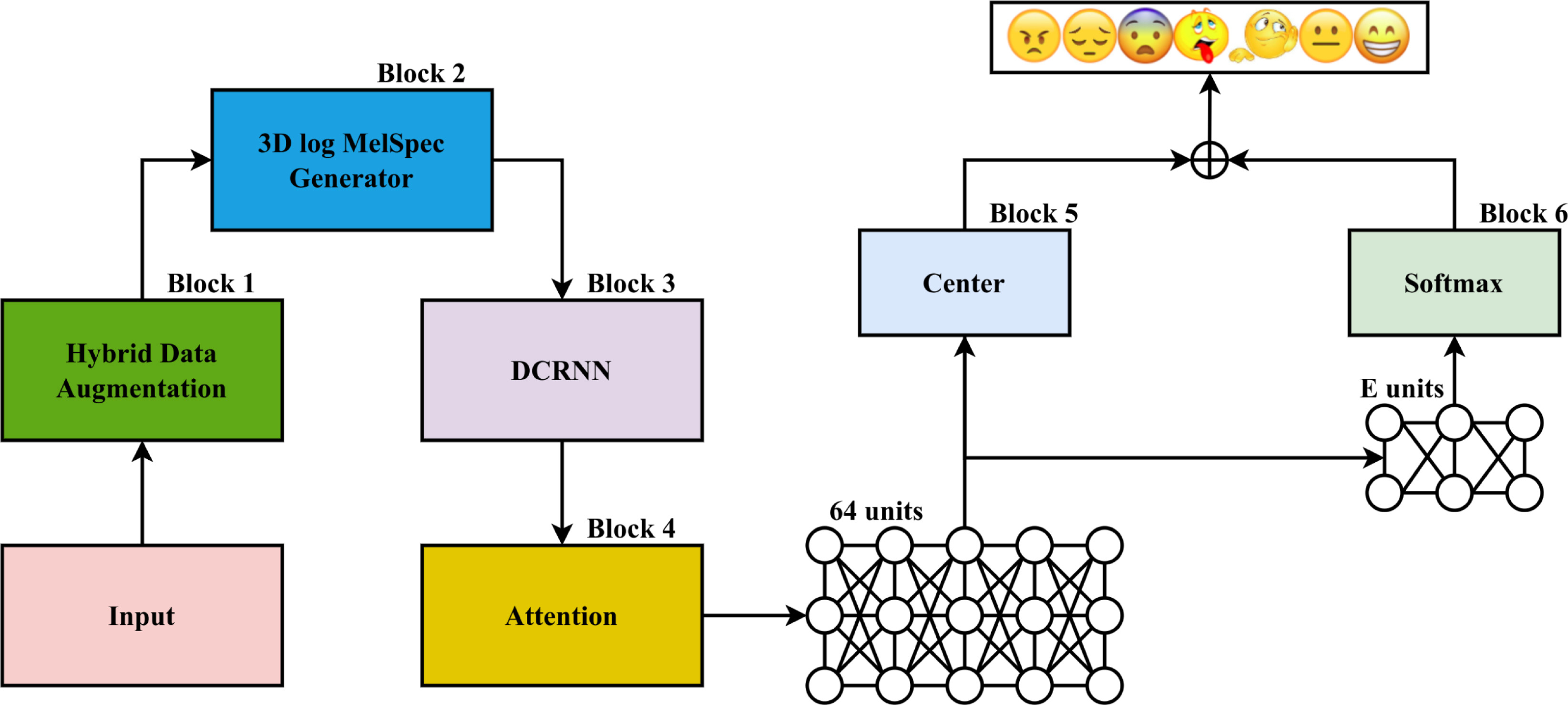
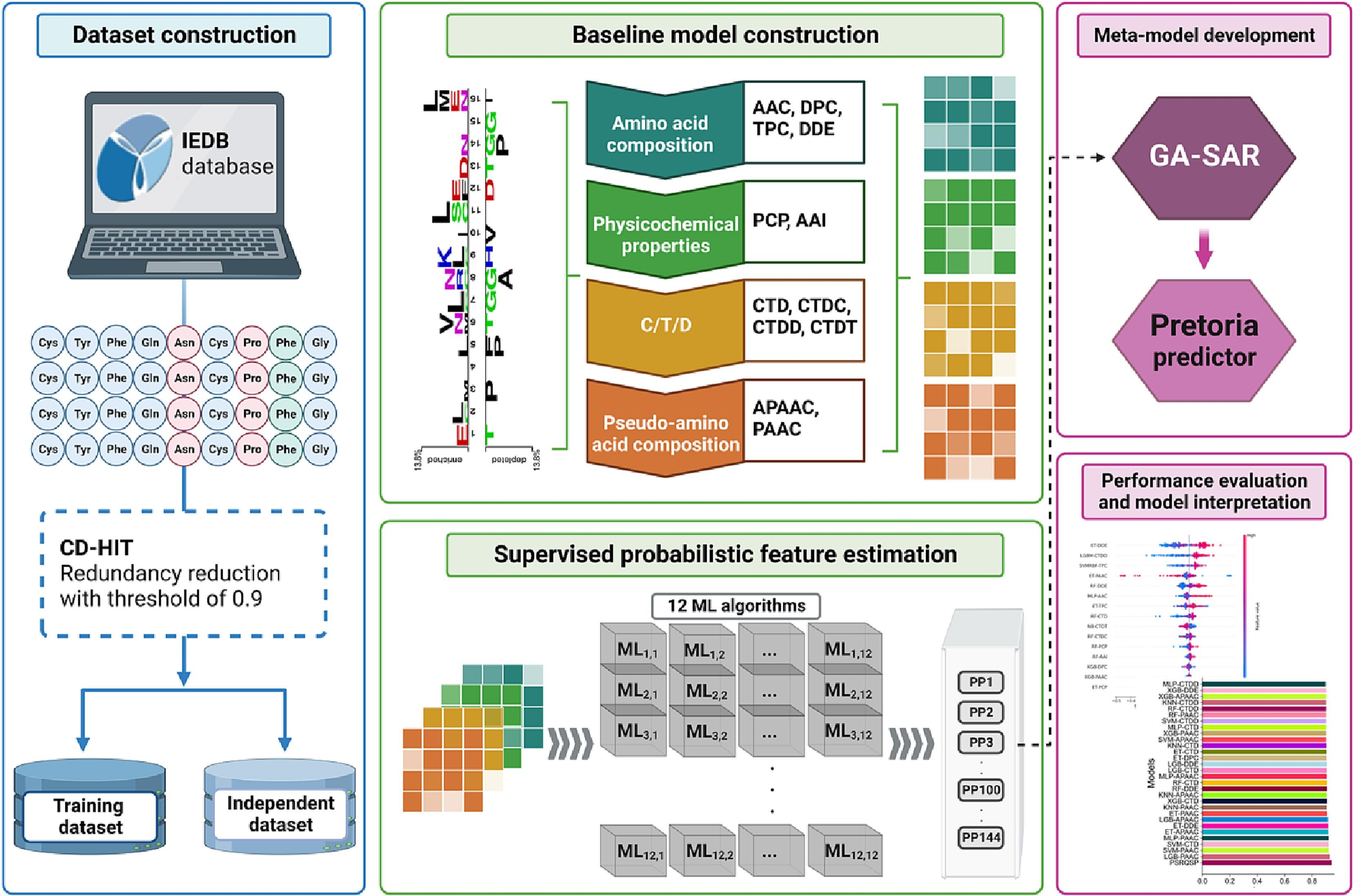
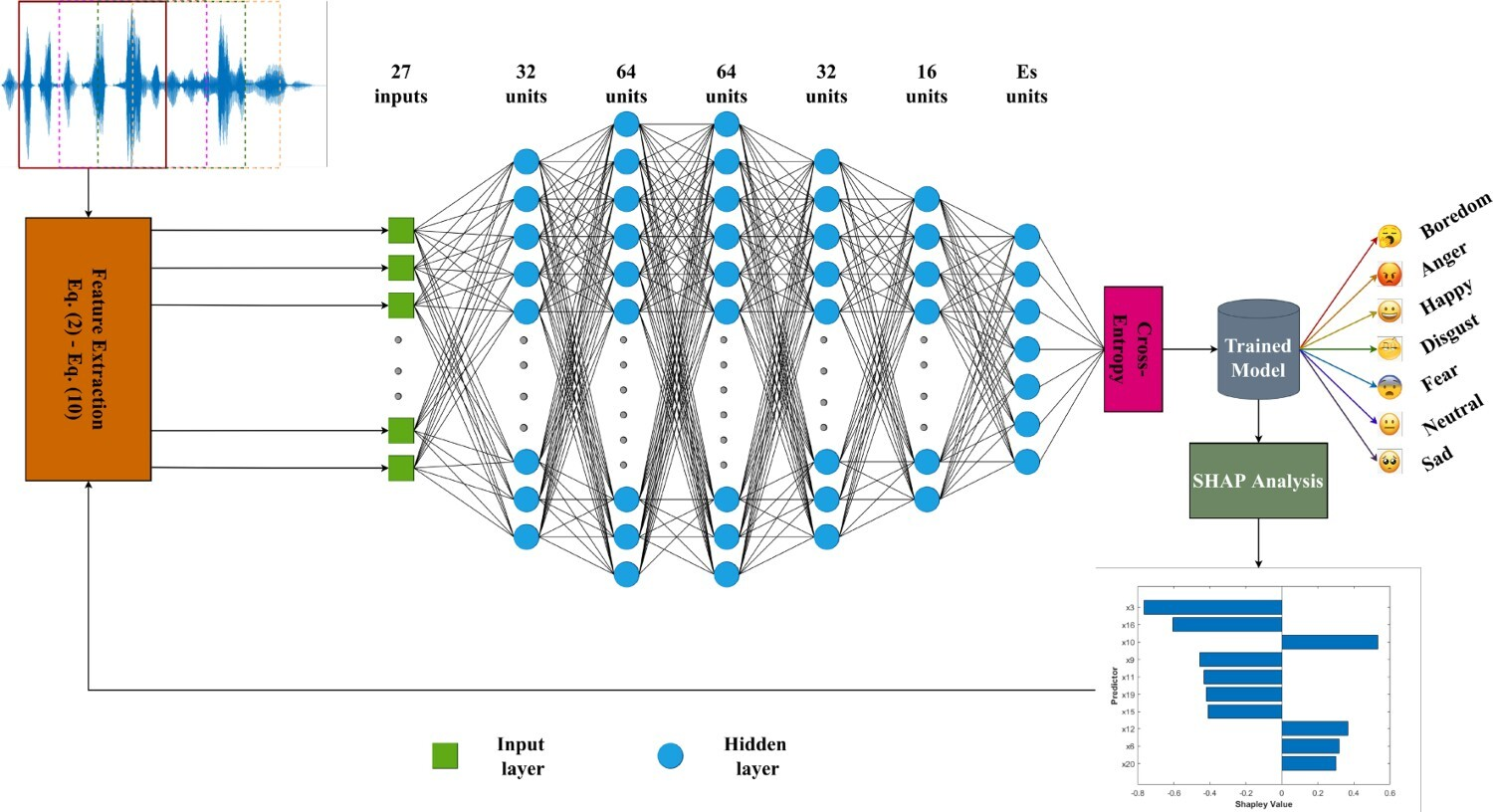
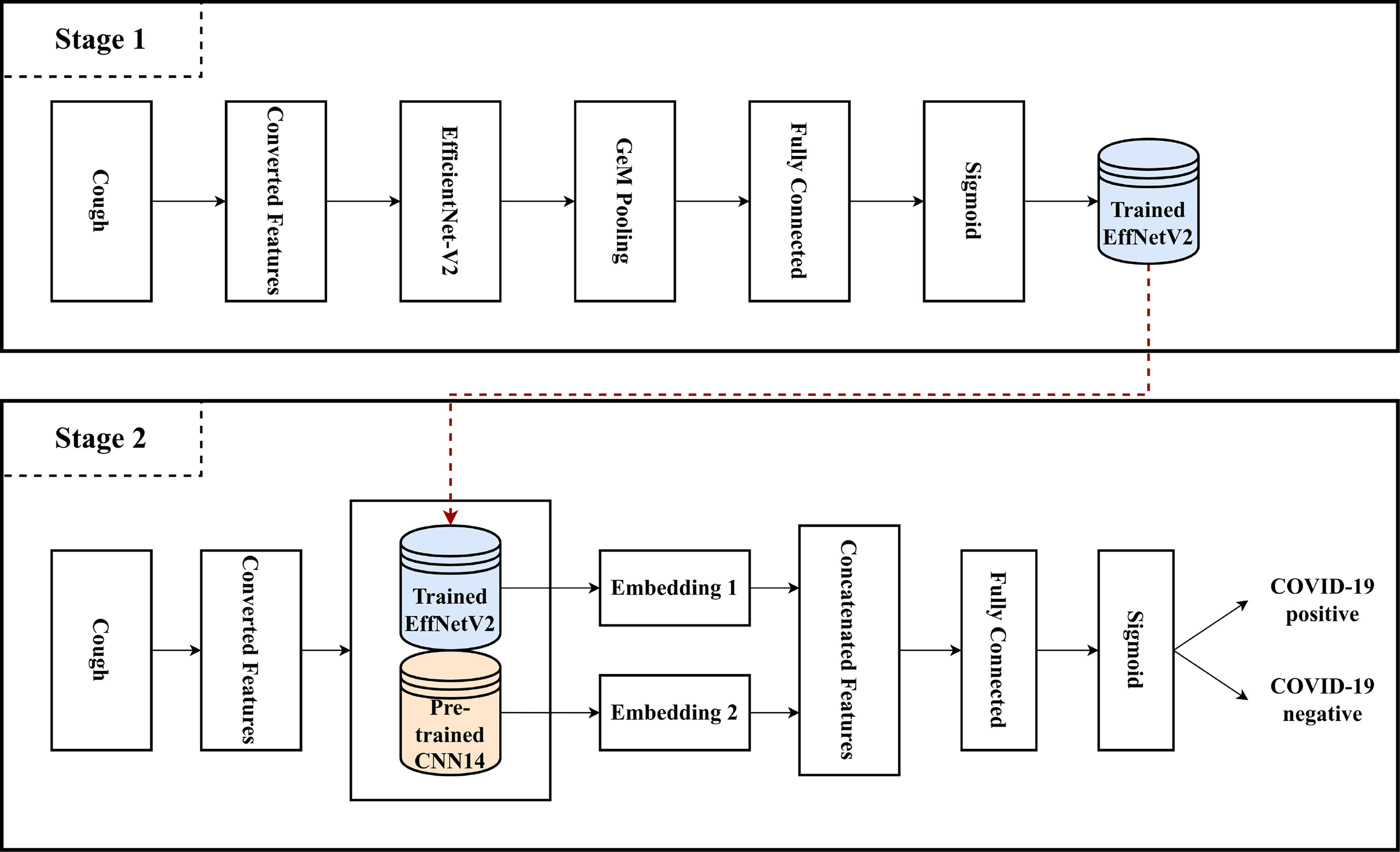
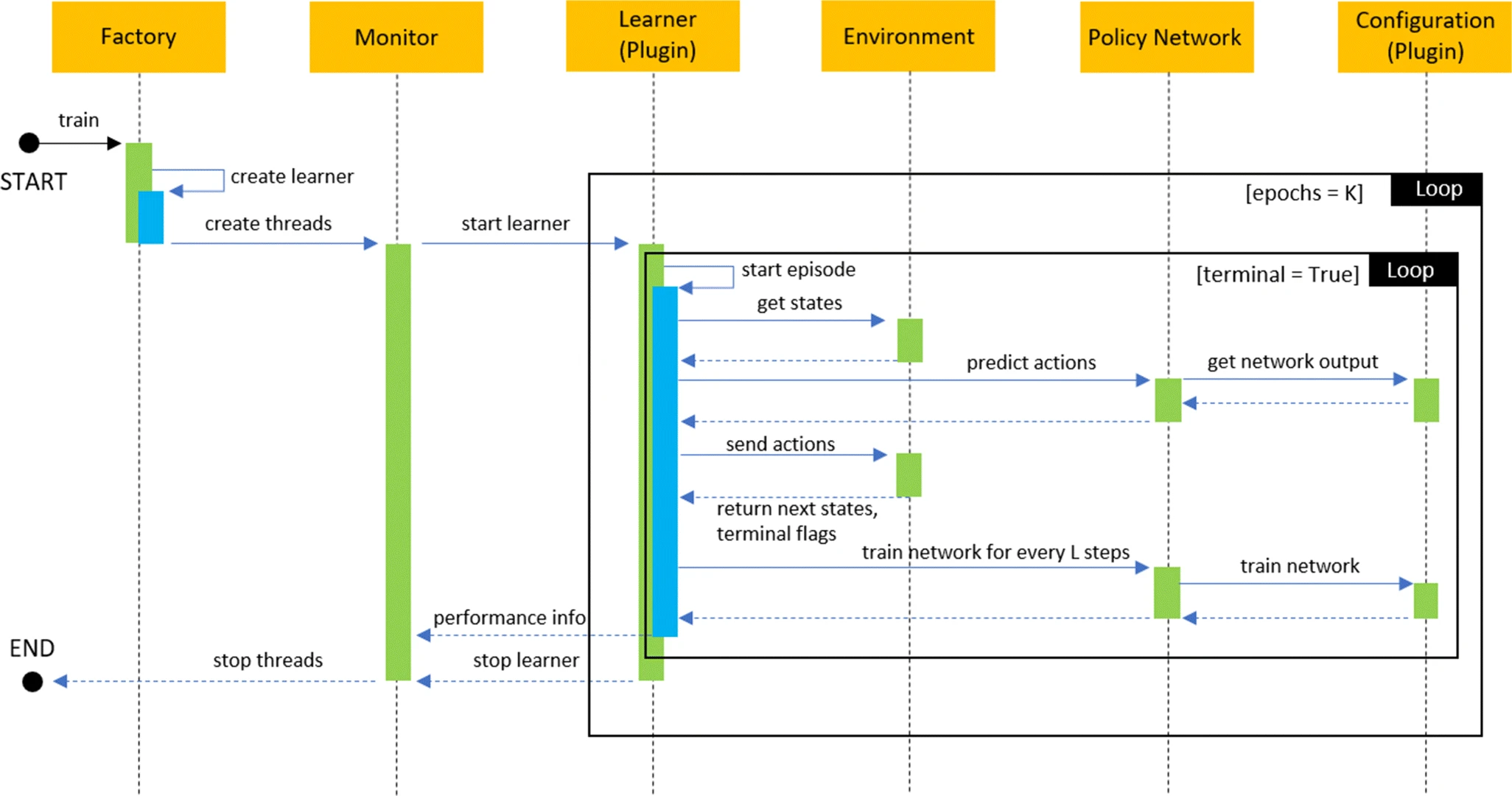
2022
- Speech emotion recognition: A brief review of multi-modal multi-task learning approachesNhat Truong Pham , Anh-Tuan Tran , Bich Ngoc Hong Pham , Hanh Dang-Ngoc , Sy Dzung Nguyen , and Duc Ngoc Minh Dang
Speech emotion recognition (SER) has become an attention-grabbing topic in recent years thanks to the development of deep learning in the field of speech processing. However, it is difficult to recognize an accurate emotional state from only speech signals. Therefore, researchers have investigated multi-modalities such as speech, visual, and text inputs to improve the emotional recognition rate of speech. In addition, to enhance the generalized deep learning models for SER, multi-task learning (MTL) strategies have also been applied in the past decade. In this paper, a brief and comprehensive review of multi-modal multi-task learning (3MTL) approaches for recognizing emotional states from speech signals is presented, including multi-modal SER, multi-task learning SER, and multi-modal multi-task learning SER. This paper also discusses about some problems that still need to be solved in 3MTL SER and gives some suggestions for the future.
@inproceedings{pham2022speech, title = {Speech emotion recognition: A brief review of multi-modal multi-task learning approaches}, author = {Pham, Nhat Truong and Tran, Anh-Tuan and Pham, Bich Ngoc Hong and Dang-Ngoc, Hanh and Nguyen, Sy Dzung and Dang, Duc Ngoc Minh}, booktitle = {International Conference on Advanced Engineering Theory and Applications}, pages = {605--615}, year = {2022}, organization = {Springer}, doi = {10.1007/978-981-99-8703-0_50}, } - Priority-Based Uplink Raw Slot Utilization in the IEEE 802.11 ah NetworksDuc Ngoc Minh Dang , Anh Khoa Tran , and Nhat Truong Pham
The IEEE 802.11ah standard allows an Access Point (AP) to connect up to 8192 stations at a transmission range of up to 1 km. The goal of the IEEE 802.11ah standard is to maintain wide connectivity and energy efficiency. Some stations are allocated to RAW slots, but they do not have uplink data packets to transmit results in low channel efficiency. The new MAC protocol (PUT-MAC) allows stations to use adjacent RAW slots in a priority manner to improve channel access usage efficiency. The stations use different Arbitration Inter Frame Space and contention window values to contend channel in the same RAW slot. The paper conducts simulations to compare the network performance of the PUT-MAC protocol with the IEEE 802.11ah.
@inproceedings{dang2022priority, title = {Priority-Based Uplink Raw Slot Utilization in the IEEE 802.11 ah Networks}, author = {Dang, Duc Ngoc Minh and Tran, Anh Khoa and Pham, Nhat Truong}, booktitle = {International Conference on Advanced Engineering Theory and Applications}, pages = {143--151}, year = {2022}, organization = {Springer}, doi = {10.1007/978-981-99-8703-0_12}, } - vieCap4H Challenge 2021: Vietnamese Image Captioning for Healthcare Domain using Swin Transformer and Attention-based LSTMThanh Tin Nguyen , Long H. Nguyen , Nhat Truong Pham* , Liu Tai Nguyen , Van Huong Do , Hai Nguyen , and Ngoc Duy Nguyen
This study presents our approach on the automatic Vietnamese image captioning for healthcare domain in text processing tasks of Vietnamese Language and Speech Processing (VLSP) Challenge 2021, as shown in Figure 1. In recent years, image captioning often employs a convolutional neural network-based architecture as an encoder and a long short-term memory (LSTM) as a decoder to generate sentences. These models perform remarkably well in different datasets. Our proposed model also has an encoder and a decoder, but we instead use a Swin Transformer in the encoder, and a LSTM combined with an attention module in the decoder. The study presents our training experiments and techniques used during the competition. Our model achieves a BLEU4 score of 0.293 on the vietCap4H dataset, and the score is ranked the 3rd place on the private leaderboard. Our code can be found at https://github.com/ngthanhtin/VLSP_ImageCaptioning/ for reproducible purposes.
@article{tin2022viecap4h, title = {vieCap4H Challenge 2021: Vietnamese Image Captioning for Healthcare Domain using Swin Transformer and Attention-based LSTM}, author = {Nguyen, Thanh Tin and Nguyen, Long H. and Pham, Nhat Truong and Nguyen, Liu Tai and Do, Van Huong and Nguyen, Hai and Nguyen, Ngoc Duy}, journal = {VNU Journal of Science: Computer Science and Communication Engineering}, volume = {38}, number = {2}, year = {2022}, doi = {10.25073/2588-1086/vnucsce.369}, } - Space-Frequency Diversity based MAC protocol for IEEE 802.11 ah networksDuc Ngoc Minh Dang , Van Thau Tran , Hoang Lam Nguyen , Nhat Truong Pham , Anh Khoa Tran , and Ngoc-Hanh Dang
IEEE 802.11ah is a sub-GHz communication technology to offer longer range and low power connectivity for the Internet of Things (IoT) applications. A Restricted Access Window (RAW) is specified to decrease the collision probability. Stations are divided into groups and stations from each group attempt to access the channel by employing the Distributed Coordination Function during their assigned RAW slots. However, the network throughput is limited by a single channel MAC protocol. In this paper, Space-Frequency Diversity-based MAC protocol for the IEEE 802.11ah network (SF-MAC protocol) is proposed to allow stations of different sectors to transmit packets on different channels with the help of Forwarders. The proposed SF-MAC protocol improves the packet delivery ratio and aggregate throughput of the network.
@inproceedings{dang2022space, title = {Space-Frequency Diversity based MAC protocol for IEEE 802.11 ah networks}, author = {Dang, Duc Ngoc Minh and Tran, Van Thau and Nguyen, Hoang Lam and Pham, Nhat Truong and Tran, Anh Khoa and Dang, Ngoc-Hanh}, booktitle = {2022 International Conference on Advanced Technologies for Communications ATC}, pages = {159--164}, year = {2022}, organization = {IEEE}, doi = {10.1109/ATC55345.2022.9943042}, } - Key Information Extraction from Mobile-Captured Vietnamese Receipt Images using Graph Neural Networks ApproachVan Dung Pham , Le Quan Nguyen , Nhat Truong Pham , Bao Hung Nguyen , Duc Ngoc Minh Dang , and Sy Dzung Nguyen
Information extraction and retrieval are growing fields that have a significant role in document parser and analysis systems. Researches and applications developed in recent years show the numerous difficulties and obstacles in extracting key information from documents. Thanks to the raising of graph theory and deep learning, graph representation and graph learning have been widely applied in information extraction to obtain more exact results. In this paper, we propose a solution upon graph neural networks (GNN) for key information extraction (KIE) that aims to extract the key information from mobile-captured Vietnamese receipt images. Firstly, the images are pre-processed using U2-Net, and then a CRAFT model is used to detect texts from the pre-processed images. Next, the implemented TransformerOCR model is employed for text recognition. Finally, a GNN-based model is designed to extract the key information based on the recognized texts. For validating the effectiveness of the proposed solution, the publicly available dataset released from the Mobile-Captured Receipt Recognition (MC-OCR) Challenge 2021 is used to train and evaluate. The experimental results indicate that our proposed solution achieves a character error rate (CER) score of 0.25 on the private test set, which is more comparable with all reported solutions in the MC-OCR Challenge 2021 as mentioned in the literature. For reproducing and knowledge-sharing purposes, our implementation of the proposed solution is publicly available at https://github.com/ThorPham/Key_infomation_extraction/.
@inproceedings{pham2022key, title = {Key Information Extraction from Mobile-Captured Vietnamese Receipt Images using Graph Neural Networks Approach}, author = {Pham, Van Dung and Nguyen, Le Quan and Pham, Nhat Truong and Nguyen, Bao Hung and Dang, Duc Ngoc Minh and Nguyen, Sy Dzung}, booktitle = {2022 6th International Conference on Green Technology and Sustainable Development GTSD}, pages = {232--237}, year = {2022}, organization = {IEEE}, doi = {10.1109/GTSD54989.2022.9989111}, } - Vietnamese Scene Text Detection and Recognition using Deep Learning: An Empirical StudyNhat Truong Pham† , Van Dung Pham† , Qui Nguyen-Van , Bao Hung Nguyen , Duc Ngoc Minh Dang , and Sy Dzung Nguyen
Scene text detection and recognition are vital challenging tasks in computer vision, which are to detect and recognize sequences of texts in natural scenes. Recently, researchers have investigated a lot of state-of-the-art methods to improve the accuracy and efficiency of text detection and recognition. However, there has been little research on text detection and recognition in natural scenes in Vietnam. In this paper, a deep learning-based empirical investigation of Vietnamese scene text detection and recognition is presented. Firstly, four detection models including differentiable binarization network (DBN), pyramid mask text detector (PMTD), pixel aggregation network (PAN), and Fourier contour embedding network (FCEN), are employed to detect text regions from the images. Then, four text recognition models including convolutional recurrent neural network (CRNN), self-attention text recognition network (SATRN), no-recurrence sequence-to-sequence text recognizer (NRTR), and RobustScanner (RS) are also investigated to recognize the texts. Moreover, data augmentation methods are also applied to enrich data for improving the accuracy and enhancing the performance of scene text detection and recognition. To validate the effectiveness of scene text detection and recognition models, the VinText dataset is employed for evaluation. Empirical results show that PMTD and SATRN achieve the highest scores among the others for text detection and recognition, respectively. For knowledge-sharing, our implementation is publicly available at https://github.com/ThorPham/VN_scene_text_detection_recognition/.
@inproceedings{pham2022vietnamese, title = {Vietnamese Scene Text Detection and Recognition using Deep Learning: An Empirical Study}, author = {Pham, Nhat Truong and Pham, Van Dung and Nguyen-Van, Qui and Nguyen, Bao Hung and Dang, Duc Ngoc Minh and Nguyen, Sy Dzung}, booktitle = {2022 6th International Conference on Green Technology and Sustainable Development GTSD}, pages = {213--218}, year = {2022}, organization = {IEEE}, doi = {10.1109/GTSD54989.2022.9989248}, } - Safety Message Broadcast Reliability Enhancement MAC protocol in VANETsDuc Ngoc Minh Dang , Anh Khoa Tran , Nhat Truong Pham , Khanh Duong Tran , and Hanh Ngoc Dang
Recently, Vehicular Ad-hoc Networks (VANETs) have been considered as an important part of the Intelligent Transportation System. Data transmission in VANET can be safety message and non-safety message transmissions. While the safety message transmission typically requires bounded delay and a high packet delivery ratio, the non-safety message transmission demands sufficiently high throughput. In this paper, a MAC protocol for Safety message broadcast Reliability Enhancement in VANETs, named SRE-MAC protocol, is proposed to ensure both the reliability of safety message transmission and the high throughput for non-safety data transmission. In particular, the proposed SRE-MAC employs a time slot allocation of TDMA and a random-access technique of CSMA schemes for accessing the control channel. To evaluate our proposed SRE-MAC protocol, some extensive simulations are conducted. The simulation results show that the proposed SRE-MAC protocol achieves higher performance in terms of safety packet delivery ratio and throughput of non-safety packets, as compared to the IEEE 1609.4 and the VER-MAC protocol.
@inproceedings{dang2022safety, title = {Safety Message Broadcast Reliability Enhancement MAC protocol in VANETs}, author = {Dang, Duc Ngoc Minh and Tran, Anh Khoa and Pham, Nhat Truong and Tran, Khanh Duong and Dang, Hanh Ngoc}, booktitle = {2022 IEEE Ninth International Conference on Communications and Electronics ICCE}, pages = {69--74}, year = {2022}, organization = {IEEE}, doi = {10.1109/ICCE55644.2022.9852052}, } - A deep learning approach for detecting drill bit failures from a small sound datasetThanh Tran , Nhat Truong Pham , and Jan LundgrenScientific Reports, 2022
Monitoring the conditions of machines is vital in the manufacturing industry. Early detection of faulty components in machines for stopping and repairing the failed components can minimize the downtime of the machine. In this article, we present a method for detecting failures in drill machines using drill sounds in Valmet AB, a company in Sundsvall, Sweden that supplies equipment and processes for the production of pulp, paper, and biofuels. The drill dataset includes two classes: anomalous sounds and normal sounds. Detecting drill failure effectively remains a challenge due to the following reasons. The waveform of drill sound is complex and short for detection. Furthermore, in realistic soundscapes, both sounds and noise exist simultaneously. Besides, the balanced dataset is small to apply state-of-the-art deep learning techniques. Due to these aforementioned difficulties, sound augmentation methods were applied to increase the number of sounds in the dataset. In this study, a convolutional neural network (CNN) was combined with a long-short-term memory (LSTM) to extract features from log-Mel spectrograms and to learn global representations of two classes. A leaky rectified linear unit (Leaky ReLU) was utilized as the activation function for the proposed CNN instead of the ReLU. Moreover, an attention mechanism was deployed at the frame level after the LSTM layer to pay attention to the anomaly in sounds. As a result, the proposed method reached an overall accuracy of 92.62% to classify two classes of machine sounds on Valmet’s dataset. In addition, an extensive experiment on another drilling dataset with short sounds yielded 97.47% accuracy. With multiple classes and long-duration sounds, an experiment utilizing the publicly available UrbanSound8K dataset obtains 91.45%. Extensive experiments on our dataset as well as publicly available datasets confirm the efficacy and robustness of our proposed method. For reproducing and deploying the proposed system, an open-source repository is publicly available at https://github.com/thanhtran1965/DrillFailureDetection_SciRep2022/.
@article{tran2022deep, title = {A deep learning approach for detecting drill bit failures from a small sound dataset}, author = {Tran, Thanh and Pham, Nhat Truong and Lundgren, Jan}, journal = {Scientific Reports}, volume = {12}, number = {1}, pages = {9623}, year = {2022}, publisher = {Nature Publishing Group UK London}, doi = {10.1038/s41598-022-13237-7}, } - Improving ligand-ranking of AutoDock Vina by changing the empirical parametersT Ngoc Han Pham , Trung Hai Nguyen , Nguyen Minh Tam , Thien Y. Vu , Nhat Truong Pham , Nguyen Truong Huy , Binh Khanh Mai , Nguyen Thanh Tung , Minh Quan Pham , Van V. Vu , and Son Tung Ngo
AutoDock Vina (Vina) achieved a very high docking-success rate, p̂, but give a rather low correlation coefficient, R, for binding affinity with respect to experiments. This low correlation can be an obstacle for ranking of ligand-binding affinity, which is the main objective of docking simulations. In this context, we evaluated the dependence of Vina R coefficient upon its empirical parameters. R is affected more by changing the gauss2 and rotation than other terms. The docking-success rate p̂ is sensitive to the alterations of the gauss1, gauss2, repulsion, and hydrogen bond parameters. Based on our benchmarks, the parameter set1 has been suggested to be the most optimal. The testing study over 800 complexes indicated that the modified Vina provided higher correlation with experiment Rset1=0.556±0.025 compared with RDefault=0.493±0.028 obtained by the original Vina and RVina 1.2=0.503±0.029 by Vina version 1.2. Besides, the modified Vina can be also applied more widely, giving R ≥ 0.500 for 32/48 targets, compared with the default package, giving R ≥ 0.500 for 31/48 targets. In addition, validation calculations for 1036 complexes obtained from version 2019 of PDBbind refined structures showed that the set1 of parameters gave higher correlation coefficient (Rset1=0.617±0.017) than the default package (RDefault=0.543±0.020) and Vina version 1.2 (RVina 1.2=0.540±0.020). The version of Vina with set1 of parameters can be downloaded at https://github.com/sontungngo/mvina/. The outcomes would enhance the ranking of ligand-binding affinity using Autodock Vina.
@article{pham2022improving, title = {Improving ligand-ranking of AutoDock Vina by changing the empirical parameters}, author = {Pham, T Ngoc Han and Nguyen, Trung Hai and Tam, Nguyen Minh and Y. Vu, Thien and Pham, Nhat Truong and Huy, Nguyen Truong and Mai, Binh Khanh and Tung, Nguyen Thanh and Pham, Minh Quan and V. Vu, Van and Ngo, Son Tung}, journal = {Journal of Computational Chemistry}, volume = {43}, number = {3}, pages = {160--169}, year = {2022}, publisher = {Wiley Online Library}, doi = {10.1002/jcc.26779}, } - Determination of the optimal number of clusters: a fuzzy-set based methodSy Dzung Nguyen , Vu Song Thuy Nguyen , and Nhat Truong Pham
The optimal number of clusters (Copt) is one of the determinants of clustering efficiency. In this article, we present a new method of quantifying Copt for centroid-based clustering. First, we propose a new clustering validity index named fRisk(C) based on the fuzzy set theory. It takes the role of normalization and accumulation of local risks coming from each action either splitting data from a cluster or merging data into a cluster. fRisk(C) exploits the local distribution information of the database to catch the global information of the clustering process in the form of the risk degree. Based on the monotonous reduction property of fRisk(C), which is proved theoretically, we present a fRisk-based new algorithm named fRisk4-bA for determining Copt. In the algorithm, the well-known L-method is employed as a supplemented tool to catch Copt on the graph of the fRisk(C). Along with the stable convergence trend of the method to be proved theoretically, numerical surveys are also carried out. The surveys show that the high reliability and stability, as well as the sensitivity in separating/merging clusters in high-density areas, even if the presence of noise in the databases, are the strong points of the proposed method.
@article{nguyen2022determination, title = {Determination of the optimal number of clusters: a fuzzy-set based method}, author = {Nguyen, Sy Dzung and Nguyen, Vu Song Thuy and Pham, Nhat Truong}, journal = {IEEE Transactions on Fuzzy Systems}, volume = {30}, number = {9}, pages = {3514--3526}, year = {2022}, publisher = {IEEE}, doi = {10.1109/TFUZZ.2021.3118113}, } - HCILab at Memotion 2.0 2022: Analysis of sentiment, emotion and intensity of emotion classes from meme images using single and multi modalitiesThanh Tin Nguyen , Nhat Truong Pham , Ngoc Duy Nguyen , Hai Nguyen , Long H. Nguyen , and Yong-Guk KimIn DE-FACTIFY@ AAAI, 2022
Nowadays, memes found on internet are overwhelming. Although they are innocuous and sometimes entertaining, there exist memes that contain sarcasm, offensive, or motivational feelings. In this study, several approaches are proposed to solve the multiple modality problem in analysing the given meme dataset. The imbalance issue has been addressed by using a new Auto Augmentation method and the uncorrelation issue has been mitigated by adopting deep Canonical Correlation Analysis to find the most correlated projections of visual and textual feature embedding. In addition, both stacked attention and multi-hop attention network are employed to efficiently generate aggregated features. As a result, our team, i.e. HCILab, achieved a weighted F1 score of 0.4995 for sentiment analysis, 0.7414 for emotion classification, and 0.5301 for scale/intensity of emotion classes on the leaderboard. This results are obtained by using concatenation between image and text model and our code can be found at https://github.com/ngthanhtin/Memotion2_AAAI_WS_2022/.
@inproceedings{nguyen2022hcilab, title = {HCILab at Memotion 2.0 2022: Analysis of sentiment, emotion and intensity of emotion classes from meme images using single and multi modalities}, author = {Nguyen, Thanh Tin and Pham, Nhat Truong and Nguyen, Ngoc Duy and Nguyen, Hai and Nguyen, Long H. and Kim, Yong-Guk}, booktitle = {DE-FACTIFY@ AAAI}, year = {2022}, }
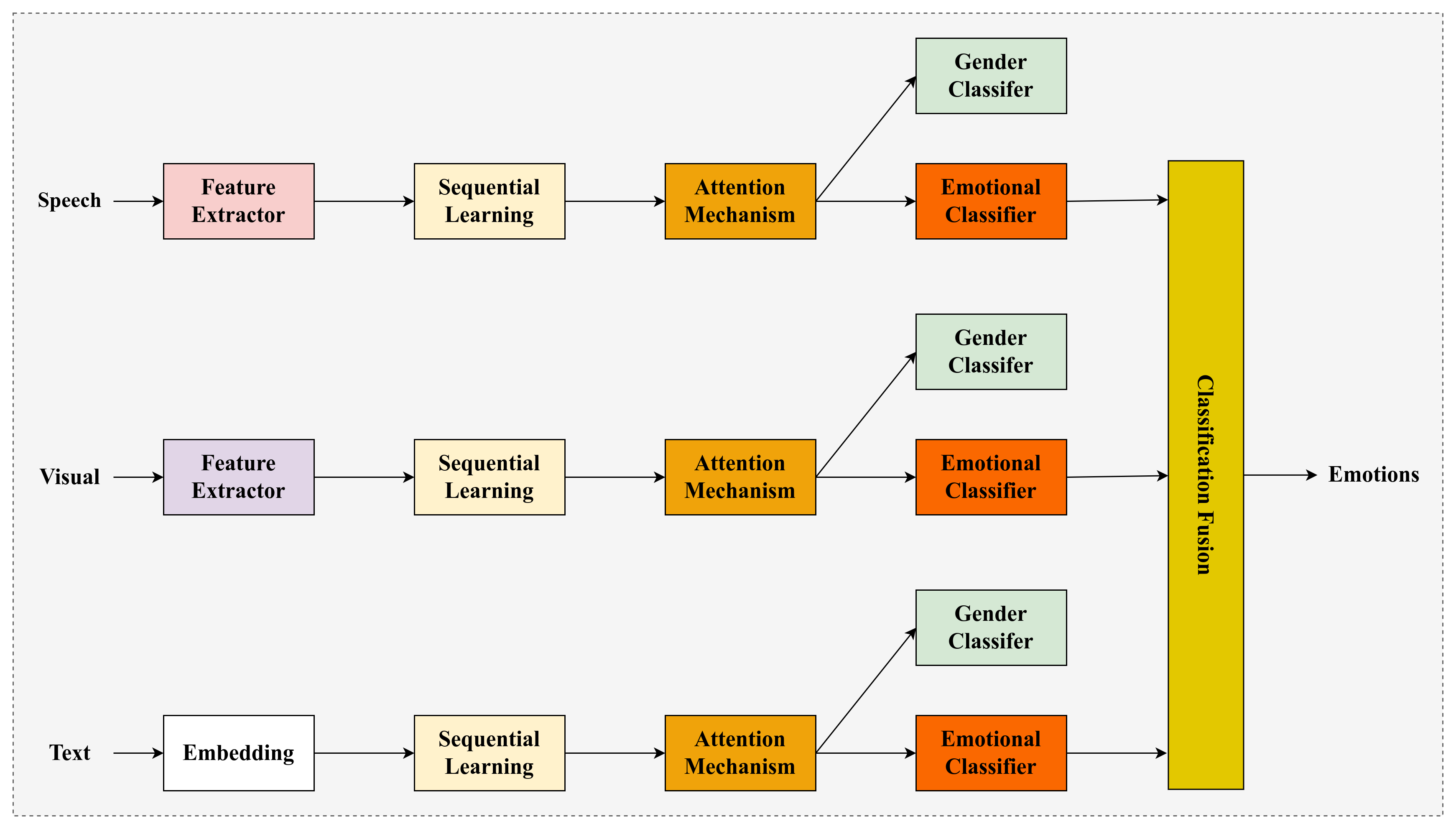
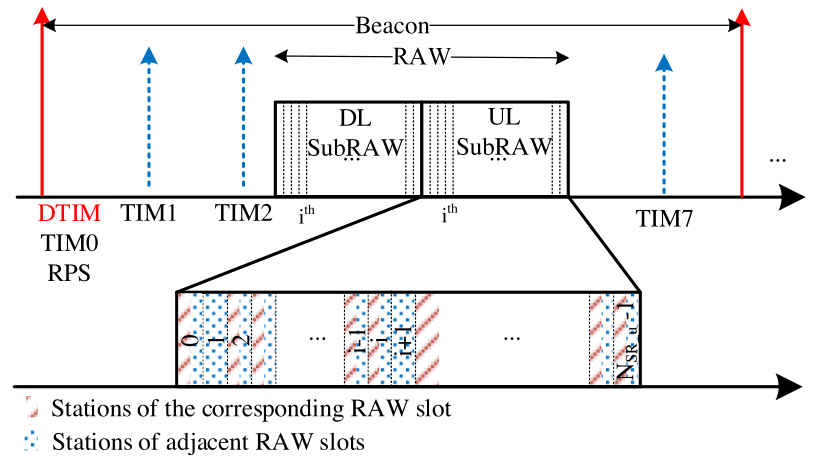

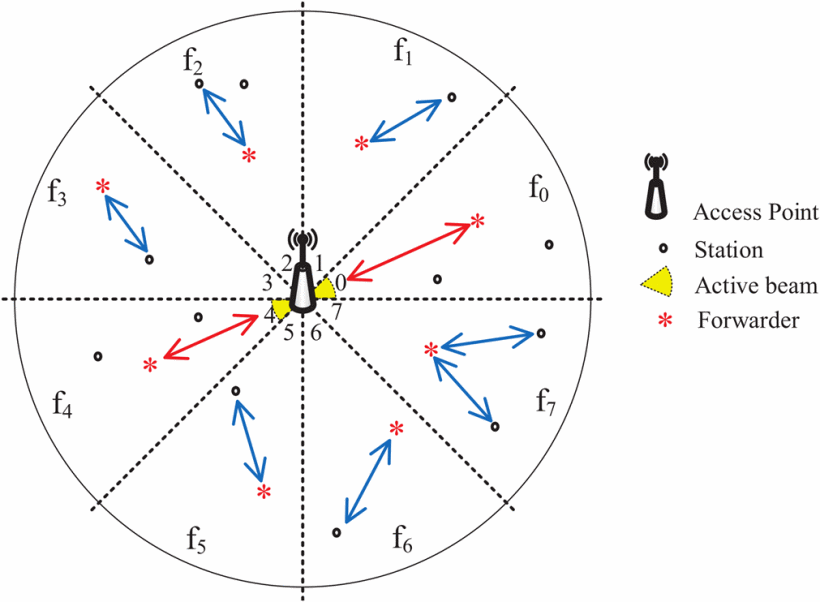


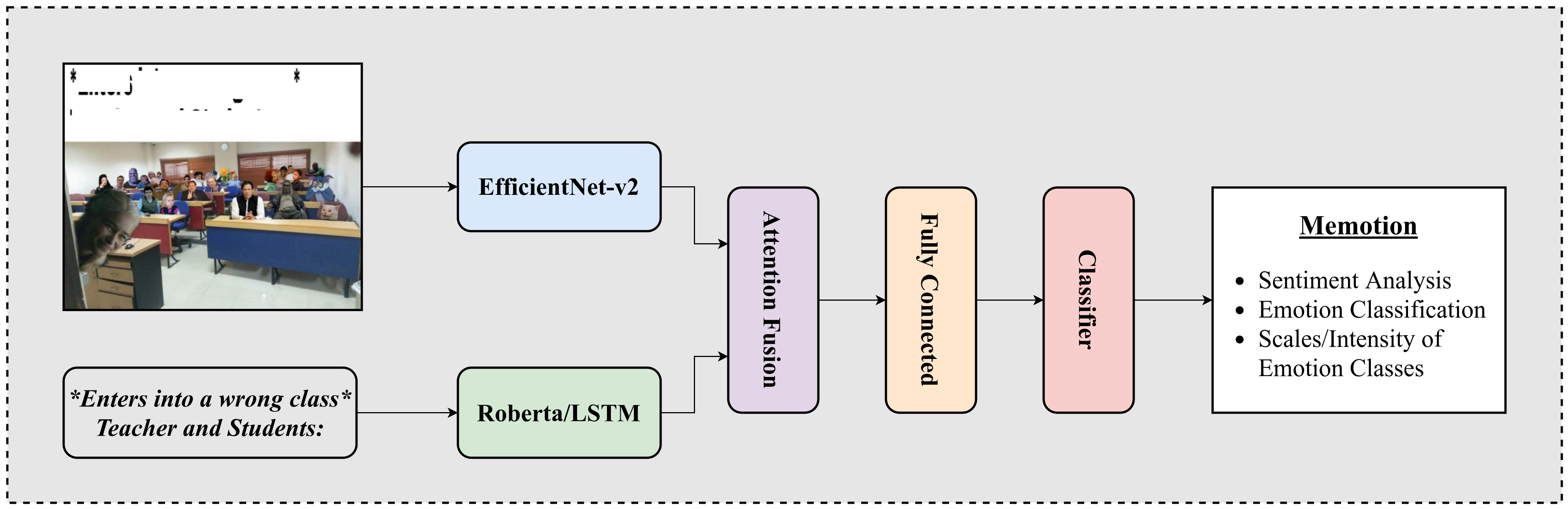
2021
- Separate sound into STFT frames to eliminate sound noise frames in sound classificationThanh Tran , Kien Bui Huy , Nhat Truong Pham , Marco Carratù , Consolatina Liguori , and Jan Lundgren
Sounds always contain acoustic noise and background noise that affects the accuracy of the sound classification system. Hence, suppression of noise in the sound can improve the robustness of the sound classification model. This paper investigated a sound separation technique that separates the input sound into many overlapped-content Short-Time Fourier Transform (STFT) frames. Our approach is different from the traditional STFT conversion method, which converts each sound into a single STFT image. Contradictory, separating the sound into many STFT frames improves model prediction accuracy by increasing variability in the data and therefore learning from that variability. These separated frames are saved as images and then labeled manually as clean and noisy frames which are then fed into transfer learning convolutional neural networks (CNNs) for the classification task. The pre-trained CNN architectures that learn from these frames become robust against the noise. The experimental results show that the proposed approach is robust against noise and achieves 94.14% in terms of classifying 21 classes including 20 classes of sound events and a noisy class. An open-source repository of the proposed method and results is available at https://github.com/nhattruongpham/soundSepsound/.
@inproceedings{tran2021separate, title = {Separate sound into STFT frames to eliminate sound noise frames in sound classification}, author = {Tran, Thanh and Huy, Kien Bui and Pham, Nhat Truong and Carrat{\`u}, Marco and Liguori, Consolatina and Lundgren, Jan}, booktitle = {2021 IEEE Symposium Series on Computational Intelligence SSCI}, pages = {1--7}, year = {2021}, organization = {IEEE}, doi = {10.1109/SSCI50451.2021.9660125}, }
2020
- A method upon deep learning for speech emotion recognitionNhat Truong Pham , Duc Ngoc Minh Dang , and Sy Dzung Nguyen
Feature extraction and emotional classification are significant roles in speech emotion recognition. It is hard to extract and select the optimal features, researchers can not be sure what the features should be. With deep learning approaches, features could be extracted by using hierarchical abstraction layers, but it requires high computational resources and a large number of data. In this article, we choose static, differential, and acceleration coefficients of log Mel-spectrogram as inputs for the deep learning model. To avoid performance degradation, we also add a skip connection with dilated convolution network integration. All representatives are fed into a self-attention mechanism with bidirectional recurrent neural networks to learn long term global features and exploit context for each time step. Finally, we investigate contrastive center loss with softmax loss as loss function to improve the accuracy of emotion recognition. For validating robustness and effectiveness, we tested the proposed method on the Emo-DB and ERC2019 datasets. Experimental results show that the performance of the proposed method is strongly comparable with the existing state-of-the-art methods on the Emo-DB and ERC2019 with 88% and 67%, respectively.
@article{pham2020method, title = {A method upon deep learning for speech emotion recognition}, author = {Pham, Nhat Truong and Dang, Duc Ngoc Minh and Nguyen, Sy Dzung}, journal = {Journal of Advanced Engineering and Computation}, volume = {4}, number = {4}, pages = {273--285}, year = {2020}, doi = {10.25073/jaec.202044.311}, }